Team Dec 26, 2022 No Comments
One of the most competitive and unpredictable business sectors is the insurance sector. It is highly related to risk. As a result, statistics have always been a factor. These days, data science has permanently altered this dependence. In this article, we will give you an insight into the various use cases of data science in insurance industry.
The information sources available to insurance firms for the necessary risk assessment have expanded. Big Data technologies are used to anticipate risks and claims, track and evaluate them, and design successful client acquisition and retention tactics. Without a doubt, data science and insurance easily compliment each other. In this article, we will have a look at the top 10 data science use cases in insurance.
Insurance companies are presently undergoing rapid digital transformation. With insurance digital transformation, a broader range of data is available to insurers. Data science in life insurance enables companies to assemble these data to effective use to drive more business and filter their product offerings. With that, let us have a look at the various applications of data science in insurance industry.
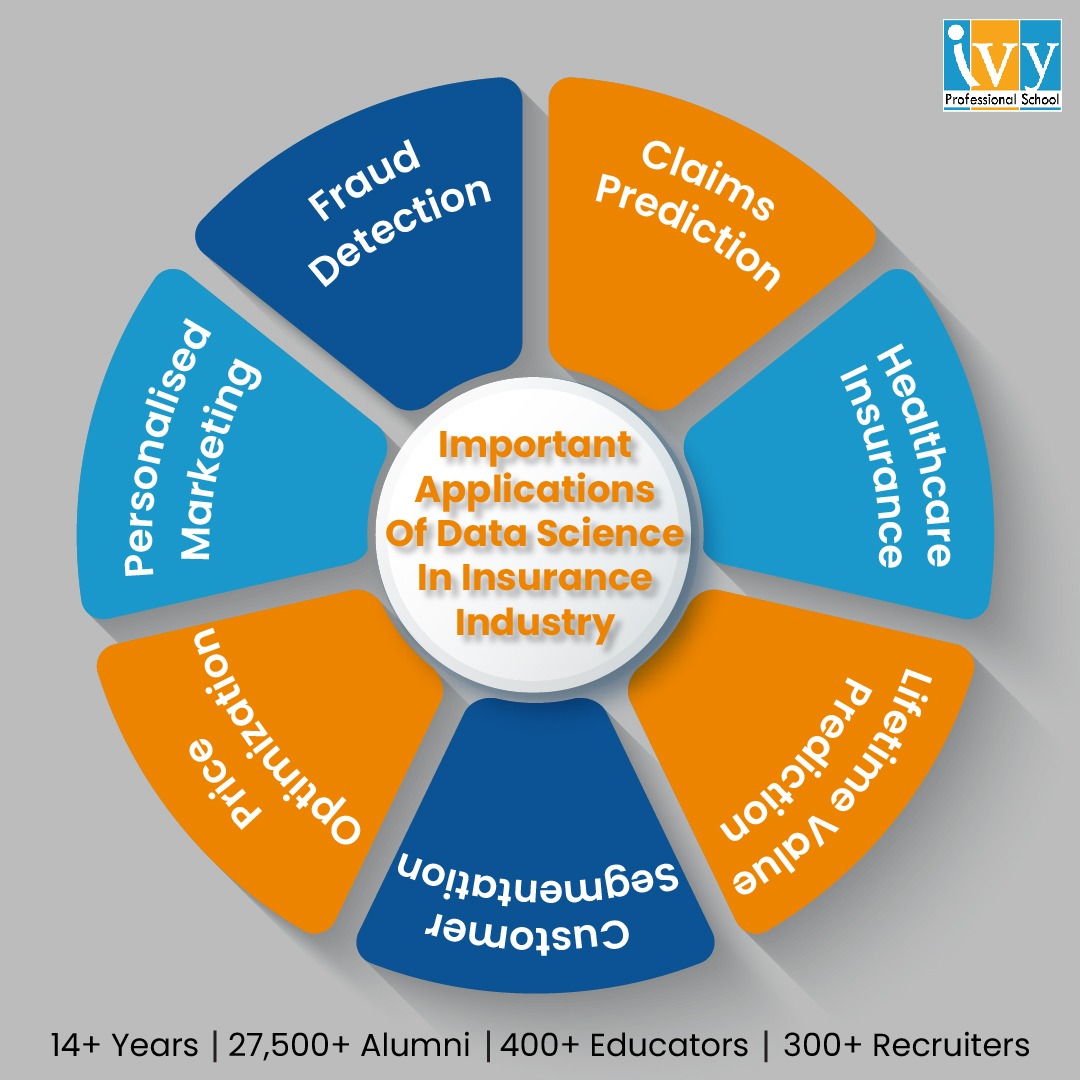
The first case among the various data science insurance use cases is the detection of fraudulent activities. Every year, insurance fraud costs insurance companies a great deal of money. It was able to identify fraudulent activities, suspicious relationships, and subtle behavioral patterns utilizing a variety of methods thanks to data science platforms and software.
A steady stream of data should be provided into the algorithm to enable this detection. Generally, insurance companies employ statistical frameworks for effective fraud detection. These frameworks depend on previous instances of fraudulent actions and use sampling methods to evaluate them. Along with that, predictive modeling techniques are used here for the purpose of analysis and also filtering of fraud scenarios. Evaluating connections between suspicious activities allows the company to identify fraud schemes that went unnoticed previously.
Customers are constantly eager to receive individualized services that completely suit their demands and way of life. In this regard, the insurance sector is hardly an exception. To satisfy these needs, insurers must ensure a digital connection with their clients.
With the aid of artificial intelligence and advanced analytics, which draw insights from a great quantity of demographic data, preferences, interactions, behavior, attitude, lifestyle information, interests, hobbies, etc., highly tailored and relevant insurance experiences are ensured. The majority of consumers like to find deals, policies, loyalty programs, recommendations, and solutions that are specifically tailored to them.
The platforms gather all relevant data in order to identify the primary client needs. Then, a prediction of what will or won’t work is made. Now it’s your turn to either create a proposal or select the one that will work best for the particular customer. This may be done with the aid of the selection and matching methods.
The personalization of policies, offers, pricing, messages, and recommendations along with a continuous loop of communication hugely contributes to the rates of the insurance company.
The idea of price optimization is complicated. As a result, it employs multiple combinations of different techniques and algorithms. Even though using this process for insurance is still up for debate, more and more insurance firms are starting to do so. This procedure entails merging data unrelated to predicted costs, risk characteristics, losses and expenses, as well as further analysis of that data. In other words, it considers the modifications compared to the prior year and policy. Price optimization and customer price sensitivity are so strongly related.
A qualitatively new level of product and service advertising has been reached thanks to modern technologies. Customers typically have different expectations for the insurance industry. Various strategies are used in insurance marketing to boost customer numbers and ensure targeted marketing campaigns. Customer segmentation emerges as a crucial technique in this regard.
According to factors like age, geography, financial sophistication, and others, the algorithms segment customers. In order to categorize all of the clients, coincidences in their attitudes, interests, behaviours or personal information are found. This categorization enables the development of solutions and attitudes especially relevant to the specific user.
CLV (Customer lifetime value) is a complicated factor portraying the value of the user to an entity in the form of the variation between the revenue gained and the expenses made projected into the whole future relationship with a user.
To estimate the CLV and forecast the client’s profitability for the insurer, consumer behaviour data is often used. The behaviour-based models are so frequently used to predict cross-selling and retention. Recency, the monetary value of a customer to a business, and frequency are seen to be crucial variables when estimating future earnings. To create the prediction, the algorithms compile and analyse all the data. This makes it possible to predict whether customers will maintain their policies or cancel them based on their behaviour and attitudes. The CLV forecast may also be helpful for developing marketing strategies because it puts customer insights at your disposal.
Healthcare insurance is a broad phenomenon across the globe. It generally implies the coverage of costs created by the accident, disease, disability, or death. In many nations, the policies of healthcare insurance are effectively supported by the governing bodies.
In this era of quick digital data flow, this niche cannot resist the influence of various data analytics applications. The global healthcare analytics market is constantly evolving. Insurance companies suffer from continuous pressure to offer better services and decrease their costs.
A broad range of data that includes insurance claims data, provider data and membership, medical records and benefits, case and customer data, internet data, and many more are assembled, framed, processed, and turned into valuable results for the healthcare insurance business. As a result, factors like cost savings, healthcare quality, fraud protection and detection, and consumer engagement may all greatly improve.
The future forecast piques the interest of insurance firms greatly. The potential to lessen the company’s financial loss is provided by accurate prediction.
For this, the insurers employ some complicated procedures. A decision tree, a random forest, a binary logistic regression, and a support vector machine are the main models. In order to reach all levels, the algorithms implement high dimensionality and incorporate the detection of missing observations as well as the discovery of relationships between claims. The portfolio for each customer is created in this way.
When talking about data science for insurance, we can conclude that modern technology is advancing quite quickly and entering many different industries. The insurance sector does not lag behind the others in this regard. Statistics have long been used in the insurance industry. Therefore, it is not unexpected that insurance companies are utilizing data science analytics in a big way.
The goal of using data science in insurance is much the same as it is in other industries: to improve the business, increase revenue, and lower expenses.
By now you must have understood the benefits data science has in the insurance sector. And not only in the insurance sector, but data science also finds relevance in almost all sectors of the world. So if you are aiming for a career as an insurance data scientist then this is the time. But before you enter this industry, it is important for you to grab a certificate in the same. Ivy Professional School offers great courses in data science and data engineering that you can enrol in. They offer expert-led courses along with complete placement assistance. Join Ivy and get to work on real-life insurance data science projects to make your resume more reachable to recruiters. For more details visit their website.
There are various applications of data science that include Claim Prediction, Healthcare Insurance, Lifetime Value Prediction, Customer Segmentation, Price Optimization, Personalised Marketing, and Fraud detection.
Using a plethora of data that is presently available, the insurance industry is seeing immense growth. Data anticipate how the industry will operate and also how its relation will be with its customers.
The job role of a data analyst in the insurance industry is to extract, convert, and summarise data as input for studies and reports, and data analysts design, alter, and run computer programmes. Examine the accuracy of the data that insurance firms offer, both in transactional detail and in aggregate, and assist the companies in fixing mistakes.
Team Dec 15, 2022 No Comments
The varied use of big data in all sectors of our life from transportation to commerce makes us realize how crucial it is in our daily lives. In the same way, data science is transforming the healthcare sector. In this article, we are going to have a look at how data science in healthcare can bring about a big and distinctive change.
Nearly 3.5 billion US dollars have been invested in digital health startups and in healthcare data science projects in 2017 enabling companies to meet their ambition of revolutionizing the general notion of healthcare that the world carries. If you are aiming to pursue a career in data science in the healthcare domain, then this is the ideal article for you as you will find many data science in healthcare jobs.
There are numerous factors that make data science crucial in healthcare in the present time, the most crucial of them being the competitive demand for important data in the healthcare niche. The collection of data from the patient via effective channels can help offer enhanced quality healthcare to users. From health insurance providers to doctors, all of them depend on the collection of factual data and its exact analysis to make effective decisions about the health situations of the patients.

Nowadays, diseases can be anticipated at the earliest stage with the help of data science in healthcare, that too remotely with innovative appliances boosted by ML (Machine Learning). Smart devices and mobile applications constantly assemble data about blood pressure, heartbeat rates, sugar, and so on transferring this data to the doctors as real-time updates, who can structurize treatments accordingly.
The significant contribution of data science in the pharmaceutical industry is to offer the groundwork for drug synthesis using AI. The metadata of the patient and mutation profiling is used for developing compounds that point towards the statistical correlation between the attributes.
Presently, AI platforms and chatboxes are structured by data scientists to allow people to get a better evaluation of their health by putting in several health data about themselves and getting a precise diagnosis. Along with that, these channels also assist users with health insurance policies and guide them to a better lifestyle.
The present-day scenario of the IoT (Internet of Things), which assures optimum connectivity is a blessing of data science. Presently, when this technology is applied to the medical arena, it can help supervise patient health. Presently, physical fitness supervises and smartwatches are used by people to manage and track their health. Along with that, these wearable sensor devices can be monitored by a doctor if they are given access and in chronicle cases, the doctor can remotely offer solutions to the patients.
Data scientists have developed wearable devices for public health that will allow doctors to collect most of the data such as sleep patterns, heart rates, stress levels, blood glucose, and even brain activity. With the help of various data science tools and also machine learning algorithms, doctors can track and detect common scenarios such as respiratory or cardiac diseases.
Data science technology can also anticipate the slightest alterations in the health indicators of the patients and anticipate possible disorders. Several wearables and also home devices as a part of an IoT network employ real-time analytics to anticipate if a patient will encounter any issue based on their current scenario.
A crucial part of medical services, diagnosis can be made more convenient and quicker by data science applications in the healthcare domain. Not only does the data analysis of the patient boosts early detection of health problems, but medical heatmaps pertaining to demographic patterns of issues can also be made.
A predictive analytics model uses historical data, evaluates patterns from the data, and offers precise predictions. The data could imply anything from the blood pressure and body temperature of the patient to the sugar level.
Predictive models in data analytics associate and correlates each data point to symptoms, diseases, and habits. This allows the identification of the stage of the disease, the extent of damage, and the appropriate treatment measure. Predictive analytics in the healthcare domain also helps:
Healthcare professionals seldom use several imaging technologies such as MRI, X-Ray, and CT Scan to visualize the internal system and organs of your body. Image recognition & deep learning technologies in health Data Science enable the detection of minute deformities in these scanned pictures, allowing doctors to plan an impactful treatment strategy.
Along with that, health data scientists are continuously working on the development of more advanced technologies to improve image analysis. For instance, the latest publication in Towards Data Science, the Azure Machine Learning channel can be used in training and optimizing a structure to detect the presence of three common brain tumors, Meningioma tumors, Glioma tumors, and Pituitary tumors.
As a data scientist in the healthcare and pharmaceutical industry, you will have to use your analytical skills to diagnose illness precisely and save lives. The huge amount of data that is sourced from the healthcare niche, from patient data to records kept by government authorities need a skilled analyst to handle it all.
The Covid-19 pandemic has lately shown how important data science in healthcare can be. Not only has data science enhanced the sampling and collection of data but also demonstrated global patterns in the spread of the infection, anticipating the next region where Covid would spread and how government policies can be structured to fight against the contagious disease effectively.
Regarding national-level healthcare, data scientists can help in monitoring the spread of the disease within the nation and coordinate in accordance with the authorities to send resources to the most affected areas.
In this section, we will outline the important responsibilities of a healthcare data scientist:
Evaluating the role of data science in healthcare is also an important responsibility for a data scientist in the healthcare domain. It includes modifying assembled data to align with the objectives and aims of the company.
Here are some of the top advantages of data science in healthcare that you can think of:

Perhaps the most crucial utilization of data science in healthcare is to decrease errors in the process of treatment via accurate anticipations and prescriptions. Since a substantial portion of data about the medical history of the patient is collected by the data scientists, that stored data can be employed for identifying symptoms of illness and offering a precise diagnosis. Mortality rates have significantly decreased since treatment options may now be tailored and care is given with better knowledge.
The development of medicine needs intensive research and time. However, both effort and time can be decreased by medical data science. Via the usage of case study reports, lab testing results, and previous medical and the impact of the drugs in clinical trials, machine learning algorithms can anticipate whether the drug is going to offer the desired impact on the human body.
In the case of quality treatment that needs to be taken care of, it is essential to create skill sets that can offer a precise diagnosis. Using predictive analytics, one can anticipate which patients are at greater risk and how to get in early to prevent serious damage. Along with that, the huge quantity of data requires to be managed skillfully to stop errors in administration, for which data science can be an ideal solution.
EHRs (Electronic Health Records) can be used by data science specialists in the medical arena to identify the health patterns of patients and stop unnecessary hospitalization or treatments, thus decreasing costs.
The 21st century is making lucrative use of data science in the healthcare niche to boost surgeries, operations, and patient recovery procedures. Apart from the developments in technology and the raised digitization of lifestyles, data science will also help in decreasing healthcare expenses, making quality medical amenities accessible to everyone.
We can conclude that there are various applications of data science in healthcare. The pharmaceutical and healthcare industry has heavily used data science for enhancing the lifestyles of patients and anticipating diseases at an early stage.
Along with that, with the advancements in medical image analysis, it is possible for doctors to find microscopic tumors that were previously difficult to find. Hence, it can be concluded that data science has revolutionized the healthcare sector and also the medical e
Now come to the section, where we can talk about how you can take your data science career to the next level. To establish your career in data science in the healthcare section you will have to have some sort of certification. The best institute for Data Science in this country is Ivy Professional School. Ivy offers a range of certifications that will help you in the future.
Team Dec 13, 2022 No Comments
AI is set to break all barriers. Now bots can answer all your questions in just a few seconds. If you are a tech-savvy person, by now you are aware of the latest ChatGPT 4 by OpenAi. ChatGPT is a newly launched application from OpenAI that is offering its users amazing answers to all their questions.
ChatGPT app is a highly advanced chatbot created by OpenAI. It is an AI research company that is behind products like the Dall E2 image generator and GPT3 which is the text model. This latest release which is in its beta version blew up the AI industry. People beyond this industry are actually talking about the ChatGPT 4. This AI bot has drawn interest while in its testing stage because of the high potential that it carries.
In 2020, OpenAI released ChatGPT3, which too gained a good push from the audience. But the GPT 4 is a bit different from its predecessor. It is more conversational in nature. The dialogue format makes it possible for ChatGPT 4 to follow up on questions, admit mistakes, challenge incorrect answers, and reject inappropriate requests. So, we can say that this is a sibling model to instruct GPT which is a subset of GPT 3.
In easy terms, ChatGPT is basically a chatbot where the users can ask questions and the chatbot uses AI (Artificial Intelligence) to give answers. OpenAI created this bot so that users can get both technical and non-technical responses.
ChatGPT as mentioned above is a chatbot that uses deep learning to offer text that resonates with a human and is created on GPT 3.5 language structure. This bot can respond to several questions in a natural way similar to a personal tutor, who is sound about all the subjects. But can this be called an alternative to Google, still remains a question n With that, let us have a look at some of the important features of ChatGPT 4?
This application which is trained by Artificial Intelligence and Machine Learning can offer information and answer questions via a conversation. If you are wondering how to use ChatGPT, below are the steps by which you can access ChatGPT.
ChatGPT is presently a prototype. At times it writes reasonable-sounding but factually incorrect answers. Along with that, ChatGPT seldom overuses several phrases like restating that it is a language structure trained by OpenAI. At times, it responds to harmful instructions, exhibits biased behavior, and also responds to inappropriate requests.
Recognizing the limitations in its present form, CEO of OpenAI Sam Altman posted on Twitter stating,
“…a lot of what people assume is us censoring ChatGPT is in fact us trying to stop it from making up random facts. Tricky to get the balance right with the current state of the tech. It will get better over time, and we will use your feedback to improve it.”
It was created by San Francisco-based OpenAI. A firm that also produced this year’s ground-breaking picture generator DALL-E 2 and tools like GPT-3.
A chatbot is a piece of software created to replicate human-like discussions in response to user input.
To test out ChatGPT, one can visit the OpenAI website and register. To use this service, you must register for an account with OpenAI. You might receive a notification stating that the beta is filled because the chatbot has already attracted one million users.
Team Nov 24, 2022 No Comments
Finance is among the most important sectors across the globe. Proper management of finance required a lot of time and effort, but that is not the case anymore. The use of data science in finance industry has made the job a lot easier.
By using Data Science, now people can quickly evaluate the finance and make better decisions handling finance. The use of data science in the financial sector has helped the sector in several ways.
Data Science operates as the backbone of the film. Without effective data science tools, a company could not perform effectively. The prominence of data analytics in finance sector has evolved manifold in recent years.
Presently data science is being used in the finance sector for similar reasons. Data science is an area that is used for several finance fields like fraud detection, algorithmic trading, risk analytics, and many more.
It is because of data science in finance that firms now have a better understanding and binding with their users by having an idea about their choices, which ultimately results in a rise in their profit margins. It also helps in identifying the risks and frauds and safeguarding the firm. Therefore, a data scientist is the most crucial asset to a firm without which a company cannot operate.
There are various applications of data science in the area of finance. The applications include:

Every entity incurs some risk while doing business, and it has become important to evaluate the risk before any decision is taken. Management of risk is the process by which the risk that is associated while doing business can be assessed, identified, and measures must be taken to control the risk.
It is through effective risk management only that the profits of the business can be raised in the long run. Hence, it is very crucial to evaluate the risks that a company is facing effectively. The utilization of data science in finance sector has made the method of management of risk more convenient. Evaluating the threat has become important for big companies for strategic decision-making and is known as Risk Analytics. In the case of business intelligence and data science in finance, risk analytics has become an important area.
A company can raise its security and also its trustworthiness by using risk analytics of data science. Data is the basis of risk analysis and risk management as it measures the intensity of the damage and multiplies it with the loss frequency. An understanding of problem-solving, mathematics, and statistics is crucial in the area of Risk Management for any professional.
Raw data primarily comprises unstructured data which cannot be put into a standard excel spreadsheet or a database. Data science has a prominent role in using such frameworks to evaluate data.
An entity encounters several kinds of risks which can start from the credit, market, competitors, and many more. The first step involves managing the risk of evaluating the threat. After that, prioritizing and monitoring the risk is important.
Initially, a risk analyst has to evaluate the loss and the pattern of the loss. It is also important for them to identify the source of the loss. So financial data science helps to formulate structures that help in evaluating areas.
A company can use hugely accessible data such as user information and financial transactions using which they can form a scoring structure and boost the cost. This is an important dimension of risk analysis and also management which is used in the verification of the creditworthiness of a user.
The previous payment records of a user must be studied, and then it must be evaluated whether the loan is to be paid to the juicer or not. Several companies presently employ data scientists to evaluate the creditworthiness of users using ML algorithms to evaluate the transactions created by the users.
In traditional analytics, the processing of data was in the form of batches. This implies that data was only historical in nature and not real-time. These created issues for several industries that needed real-time data for gaining exposure to the current scenario.
However, with the developments in technology and advancements of dynamic data pipelines, it is now feasible to access the data with basic latency. With this application of data science in finance, companies are able to measure credit scores, transactions, and other financial attributes without any latency issues.
User personalization is a big functionality of financial institutions. With the help of real-time analytics, data scientists can take views from consumer behaviors and are able to make prominent business decisions.
Financial institutions such as insurance companies use user analytics for measuring the customer lifetime value, raising their cross-sales along with reducing the below zero users for boosting the loss.
Financial institutions require data. And so big data has revolutionized the way in which financial institutions operate. The variety and volume of data are contributed via social media and a huge number of transactions.
The data is available in two forms:
While structured data is more convenient to manage, it is unstructured data that creates a lot of issues. This unstructured data can be managed with various NoSQL tools and can be processed with the help of MapReduce.
Another important aspect of big data is Business Intelligence. Industries use machine learning for generating insights regarding the user and extracting business intelligence. There are various tools in AI such as Natural Language Processing, text analytics, and data mining that general meaningful insights from the data.
Along with that, ML algorithms evaluate financial trends and alterations in the industry values via a thorough evaluation of the user data.
Fraud is a big issue for financial institutions. The danger of fraud has increased in the number of transactions. However, with the development of big data and also in analytical tools, it is now feasible for financial institutions to keep track of fraud.
One of the most commonly practiced financial fraud is credit card fraud. The detection of this form of fraud is because of the development of algorithms that have raised the accuracy of anomaly detection.
Along with that, these detections alert the entities regarding anomalies in financial buys, prompting them to block the accounts so as to decrease the number of losses. Several ML tools can also identify unusual patterns in trading data and notify the financial institution for further investigation into it.
Data science in finance revolves around a broad range of opportunities for investment careers. Areas that focus on technology include data science, cybersecurity, machine learning, AI, and many more.
Finally, we conclude that there are various roles of data science in finance industry. The use of data science revolves mostly around the area of risk management and analysis. Entities also use Data Science user portfolio management for evaluating trends in data via business intelligence tools.
Financial companies employ data science for the purpose of fraud detection for finding anomalous transactions and also insurance scams. Data science is also being used in algorithmic trading where ML plays an important role in making anticipation regarding the future market.
Team Nov 07, 2022 No Comments
By automating the ETL process, organized business intelligence can be derived from the collected data. You can use these ETL tools that will help you to be successful.
The most successful brands presently are completely data-driven. Whether it is Amazon, Google, TikTok, or any other company, they all use data for determining their next moves. But here is a thing. It is convenient to collect ample data. Analyzing all that data is often the most challenging job. Let us have a look at some of the ETL tool examples that you can use in data transfer. Also, there are various ETL tools free of cost, but it is always advised to go with the ones that are mentioned below.
Companies and industries of all sizes presently have access to the ever-rising amount of data, far too broad for any human to comprehend. All this data is practically useless without a way to effectively analyze or process it, revealing data-driven insight that is hidden within the noise.
The ETL process is the most famous method of collecting data from various sources and loading it into a centralized data warehouse. Data is first taken from a source, such as a database, file, or spreadsheet, converted to meet the criteria of the data warehouse, and then fed into the data warehouse during the ETL process.
Data warehousing and analytics require ETL, but not all ETL software products are made equal. The ideal ETL tool may change based on your circumstances and use cases. Here are seven of the top ETL software solutions for 2022 along with a few more options you might want to take into account:
Informatica’s PowerCenter is an enterprise-grade data management system despite having an intuitive graphical user interface. It is an AI-powered platform that covers both on-premises and cloud-based ETL requirements. Additionally, it supports many clouds, hybrid, and multiple clouds, as well as unique ETL rules.
You can accomplish all of your ETL requirements with PowerCenter, including analytics, data warehouse, and data lake solutions. Extensive automation, high availability, distributed processing, interfaces to all data sources, automatic data validation testing, and dynamic partitioning are just a few of Informatica PowerCenter’s many features.
The creation of high-performance data integration, transformation, and migration solutions may be done affordably thanks to Microsoft SQL Server Integration Services (SSIS). It incorporates data warehousing extract, transform, and load (ETL) functionalities. The SSIS program can be used to clean data, put it into warehouses, copy or download files, administrate SQL Server objects or data, or mine data.
You might also want to consider SSIS when loading data, like flat files, relational databases, and XML files, from various sources.
Talend provides a number of options for centrally managing and integrating data. That includes Stich Data Loader, Big Data Platform, and Talend OpenStudio. For managing on-premises and cloud data, the Talend Data Fabric offers end-to-end data integration and governance.
Environments in the cloud, hybrid cloud, and multi-cloud are supported. Additionally, it is compatible with almost every public cloud service provider and cloud data warehousing. You will also have numerous built-in integrations to work with so that it becomes convenient for you to extract and transform data from literally any source and load it to any destination you wish. You can also improve the capabilities of your Talend edition by adding tools for app integration, Big Data, and other data solutions.

Businesses wishing to gather, process, and analyze data related to online sales can use the low-code data integration platform offered by Integrate.io. It is simple to interface with NetSuite, BigCommerce, Magento, and Shopify. However, it also has features that are helpful in other fields, such as healthcare, SaaS, and e-learning.
Any source that supports RestAPI can have data extracted with Integrate.io. If there isn’t a RestAPI currently, you can create one with the Integrate.io API Generator. Once the data is transformed, you will be able to load it into several destinations like NetSuite, data warehouse, databases, or Salesforce.
Telend’s Stitch is a completely managed, open-source ETL service that has ready-to-query schemas and also a user-friendly interface. The data integration service can source data from more than 130 platforms, services, and applications. After that, the data can be routed to more than 10 varied destinations. That includes Snowflake, Redshift, and PostgreSQL.
With a no-code technology, integrating your data in a warehouse won’t require you to write any code. You can expand its capabilities as your demands change because it is scalable and open-source. Additionally, it offers tools for internal and external data governance compliance.

The Pentaho solution makes retrieving, cleaning, and cataloging data convenient so that varied teams can use it in a consistent format. Access to IoT data is made easier by the tool for machine learning applications. Additionally, it is very scalable, allowing you to quickly and on-demand examine enormous amounts of data.
The desktop client for Spoon is also available from Pentaho Data Integration. You can use the tool to create transformations, plan jobs, and manually begin processing activities. Real-time ETL can be used with PDI as a data source for Pentaho Reporting. Additionally, it provides OLAP services and no-code operations.

The key benefit of Oracle Data Integrator is that it imports data into the destination first, then transforms it (ELT vs. ETL) utilizing the capabilities of the database or Hadoop cluster. However, ODI provides access to additional potent data management and integration features via a flow-based declarative user interface. Deep integration with Oracle GoldenGate, high-performance batch loading, and SOA-enabled data services are all examples of this.
ODI has long offered a tried-and-true platform for high-volume data operations across a range of use cases. With Oracle Enterprise Manager, monitoring is also comparatively simple.
Hevo is a real-time, completely managed, no-code data solution that gathers data from over 150 sources and processes it. Additionally, it loads the normalized data into the desired destination as necessary.
You may import data into 15 different data warehouses from a variety of sources, including NoSQL databases, relational databases, S3 buckets, SaaS apps, and files.

Some of the most ideal FiveTran features involve convenient replication of data, automated schema migration, and various other connectors. Along with that, FiveTran uses refined caching layers to shift data over a safe connection without even keeping a copy on the application server.
Already-built connectors help in transforming data more quickly. These connectors are completely managed, allowing you to automate data integration without sacrificing reliability. You can anticipate complete duplication by default.
If your company depends on Google items such as Google Cloud Platform and also BigQuery databases, Aloma might be an ideal fit. The tools allow the user to unify large datasets of data from several sources into one place; BigQuery and everything in real-time.
Using ETL tools should be profitable. If you do not use them, then you will have to spend a lot on the transfer of data and associated cloud costs. So you will have to manage these charges to safeguard your margins.
Yet, without full cost visibility, enhancing costs that are related to data can be challenging. In other terms, unless you see who, why, or what changes your costs, you may have to struggle to evaluate where to cut costs without hurting your data-driven functions.
Machine Learning is the NOW! If you wish to enter this industry then there is no better time than now. All you will need is an educational experience in machine learning and AI and there is no better institute than Ivy Professional School. We are not bluffing. Ivy offers expert-led courses with relevant real-life case studies. You also get complete 1:1 career counseling absolutely free. We don’t stop here. At Ivy, get complete placement support and resume-building classes. For more details, you can visit their website.
Team Nov 02, 2022 No Comments
Data engineering is among the most in-demand career options presently and a highly profitable one at that. And if you are thinking about what data engineering holds, what will be the growth pathway, or how to become a data engineer, then you are at the right place. In this article, we are going to have a look at some of the most effective data engineering tips that you can imbibe for a better data engineering career option.
Data engineers basically create reservoirs for storing data and also take care of these reservoirs. They are generally guardians of the data which is available to companies. They manage all our personal data and also preserve it. They help in making sufficient unorganized data into data that can be used so that business analysts and also data scientists can anticipate it.
A data engineer basically arranges datasets as per the requirement of the industry. They test, construct, and maintain the primary database mechanism. They are also responsible for creating algorithms for converting data into useful structures and formulating the latest data analytics tools. Data engineers collaborate with management teams to know the aim of the company.

As stated above, data engineering is an interdisciplinary profession that needs a mixture of technical and also business knowledge to create the most impact. Beginning a career in data engineering, it is not always clear what is important to be successful. So these data engineering tips will help you in navigating your career better.
There are five primary tips that we would recommend to any data engineer who is just starting their career.
Skill is the key. It opens avenues to many new chances. Skills are required for every job role and one needs to learn the skill sets that are needed so that one can have a roadmap of what that specific job entails. The below-mentioned skills are needed to be a successful data engineer.
Coding is an important skill you need to work with data on a bigger scale. Python is one of the most used languages to master data science. Along with Python, you can also master Java, Scala, and many more. These are crucial for analysis.
As a data engineer, you will basically be needing to function with databases, constructing, handling, and extracting data from databases. These are basically two types of databases (DBMS) that you will work with:
Moving data from several sources of data to a single database is a part of the ETL process. By using these technologies, data can be converted into valuable data.
The ETL process involves transferring data from various sources of data to a single database. These technologies allow data to be transformed into useful data.
It’s excellent to know how to save data, but you should also be familiar with online data storage. Data is stored online using cloud computing to boost accessibility.
It helps to have a foundational understanding of machine learning. Although it is not directly related to data engineers, machine learning aids them in understanding the requirements of a data scientist.
Data engineers, like those in every other profession, must frequently communicate with a variety of people, including business analysts, data scientists, and other data engineers.
Your skills can be validated with a certificate. It gives the potential employer a sense of your abilities and experience. You can choose from a number of reputable platforms for accredited courses. You can choose professional courses and one best in the industry is from Ivy Professional School.
A certificate can be used to verify your abilities. It provides the prospective employer with information about your skills and experience. For authorized courses, you have a variety of trustworthy sites to pick from. Create a solid portfolio, do industry-level projects, and get into case studies that will help you to a great extent.
Once you get a job, you will know that data engineering is a growing career. You should keep in mind nevertheless that learning doesn’t end here. Working with data requires ongoing learning and development. Languages are constantly evolving, so it’s important to stay up with these changes if you want to advance as a data engineer. Join or start a group that focuses on data engineering and associated skills so that everyone in the community can contribute their thoughts and continue to hone their abilities.
Using your Linkedin profile, you can get in touch with various businesses or work for yourself. Share your resume with them, ask them to provide you with some work, and show your want to work for the organization and team. Your college career and confidence will grow if you work on beginner-level assignments. Extrovert yourself. Make friends with others. Every day, acquire new knowledge. You will benefit from having an internship in your early career.
Working on tasks at the introductory level will advance your academic career and confidence. Be outgoing yourself. Make new acquaintances. Learn something new every day. You will benefit from having an internship in your early career. Such a large amount of data requires laborious management. Industries can manage their data effectively thanks to data engineers. It is simple for you to find employment in this industry if you have the necessary talents and follow all the above-mentioned data engineering tips, such as coding, data storage, cloud storage, etc. Obtaining a legitimate certificate will elevate your profile.
Team Oct 19, 2022 No Comments
In the HR (Human resource) niche, decision-making is changing. At a time when the traditional ways of operating HR are no longer sufficient to keep pace with the new technologies and competition, the field is at crossroads. This is a perfect case study to find out the effectiveness of analytics in HR.
When we talk about analytics in HR there are many facets that come into play. HR analytics aims to offer insight into how effectively to manage employees and attain business goals. Because so much data is accessible, it is crucial for HR teams to initially identify which data is most relevant, along with how to use it for optimum ROI.
Modern talent analytics mix data from HR and other business operations to address challenges related to:
So, a leading Multinational Professional Service Company reached Ivy Professional School for upskilling of their HR department to obtain optimum benefit from their operations.
Upskilling as the name suggests implies taking your skill to a next level. This has various benefits for any organization and the individual as well. Upskilling is very crucial as it:
Each employee searches for a purpose in their work, and innovation comes its way when the goal of the organization aligns with individual career aims.
When an employee leaves an organization, you must fill that position, which again starts the hiring and recruiting processes.
Along with upskilling, this analytics program is aimed at creating domain knowledge among the employees in the HR department. Domain knowledge is basically the knowledge of a specific, specialized discipline or niche, in contrast to general (or domain-independent) knowledge.

Considering the characteristics of the job profile and the expectations set by the company, a special curriculum was created.
Analytics in HR is reaching new horizons now. By using people analytics you don’t have to depend on gut feeling anymore. So now many organizations are inclining towards upskilling their employees in the HR department so that they get a good domain knowledge and become a more valuable resource of their company.
You can also reach out to us if you want us to organize similar analytical programs for your organization. Please email us your requirement at info@ivyproschool.com
Team Oct 11, 2022 No Comments

Guess how much data engineers earn? An average salary of ₹7,44,500 per year in India. And senior data engineers earn between ₹11 lakhs to ₹24 lakhs per year.
And if you search for data engineering jobs on Indeed or LinkedIn, you will find over 20,000 vacancies in India alone. But why am I telling you all this?
Because I want to show how in-demand data engineers are in the market. With more and more companies relying on data to make smart decisions, data engineering has become a necessity.
Now, if you want to start a career in data engineering, you have to learn some technical and soft skills. In this post, I will tell you what those essential data engineering skills are and how you can start your career in this field.
You can think of data engineers as the architects of the data world. They build and maintain systems and architecture to collect, store, and manage data.
For example, they work with ETL (extract, transform, load) processes to combine data from multiple sources into a central repository. Similarly, they build data pipelines, work with databases, and manage data warehouses.
They basically prepare the raw data for analysis so that data analysts and data scientists can do their jobs. This way, they work together to help the company find valuable insights and make decisions that lead to business growth.
To perform all those tasks, data engineers need to gain expertise in various processes, tools, and technologies. They also need soft skills to work together as a team and communicate effectively. Here are all the skills you would need to become a pro data engineer:
Aspiring data engineers often ask me, “Is coding important?” And I always tell them that coding is one of the most important skills for data engineers. It is what will help you optimize and automate data workflows as well as improve data quality and reliability. Here are some programming languages often used in data engineering:
Python: It’s good for handling big data, automating tasks, and working with different data formats. It has a range of libraries that make data processing easier and faster.
SQL: It helps manage and query large databases. It’s also needed for data handling tasks like extracting, organizing, and updating data stored in databases.
Java: This language helps you build scalable, high-performance data pipelines. It helps you develop large, reliable systems that handle big data processing efficiently.
Scala: It helps you work with distributed data systems like Apache Spark. It’s specifically designed to handle large datasets while maintaining performance.
R: It helps in data analysis and statistical tasks. You will need it to perform complex data manipulation and generate insights from data sets.
You can go through this data engineering syllabus to learn more about technical skills that are valued in the present market.
One of the most important roles of data engineers is to store and organize raw data in data warehouses. Data warehouses are simply central repositories that allow access to real-time data for analysis and decision-making.
Without this skill, you won’t be able to manage the high volume and complex data most companies handle today. So, you need to know about data warehousing solutions like Panopoly or Amazon Redshift. This way, you can make data storage, retrieval, and processing more efficient.
Knowing programming languages isn’t enough. You also need an understanding of operating systems to design, develop, and troubleshoot systems. As a data engineer, you will work with operating systems like Linux, UNIX, macOS, and Windows because data infrastructure often runs on these platforms. For example, Linux is widely used in data engineering because of its stability, flexibility, and performance.
This data engineering skill helps you design, maintain, and optimize databases. SQL is the most widely used language for managing relational databases, allowing you to query, update, and manipulate data efficiently. You also need to learn NoSQL databases like Cassandra or Bigtable, which are better suited for handling unstructured data.
You can learn basic SQL queries, cleaning and modifying data, aggregating and analyzing data, working with multiple data tables, troubleshooting and error handling, advanced filters in SQL, data definition language, data manipulation language, using subqueries, creating user-defined functions, etc.
This is an important data engineering skill because you will often have to work with big datasets that traditional databases can’t handle. It will make you an expert at managing and processing data on a large scale.
For this, you can learn Hadoop, which includes topics like MapReduce, YARN, HDFS, data spilling, data replication, Daemons, etc. You have to learn Apache Hive to query large datasets using HiveQL. You also need to know Apache Spark, how to optimize it, and how to process data in real time. A good understanding of real-time data processing with Kafka and its integration with Spark is also important.
Microsoft Azure is a cloud platform that provides scalable, secure, and cost-effective data storage and processing solutions. So, this skill helps you build and maintain data pipelines, store data, and run large-scale analytics in the cloud.
Here, you will learn about Azure services like virtual machines, storage, and database services. Next, you can understand advanced data engineering with Azure and real-time data streaming and processing. Learning hybrid cloud scenarios, governance, and compliance is also necessary.
This data engineering skill helps you better analyze and evaluate a situation. You need this to identify problems related to data collection, storage, or analysis and then develop effective solutions. You have to come up with innovative solutions to improve the performance of the systems and the quality of the data. This is where critical thinking helps you.
As a data engineer, you will collaborate with other team members and business leaders with and without any technical expertise. So, better communication skills help you explain data processes and systems and share updates without any misunderstandings. For example, you may have to work with data scientists or analysts and share findings and suggestions. And you know, this skill not only helps you in data engineering but also in your entire life.
Now, let’s understand how to become a data engineer:
Even though formal education may not be that important these days, most employers need data engineers to hold at least a bachelor’s degree. You should hold a degree in something like computer science, computer engineering, information technology, software engineering, applied math, statistics, physics, or a related area.
You just saw the important data engineering skills in the above section. You need to master them. And one of the best ways to do it is to take a comprehensive course.
For example, Ivy Professional School’s IIT-certified Data Engineering Certification course helps you learn all the in-demand skills like SQL for data engineering, Python essentials for data, Big data processing, and Azure cloud engineering.
This 45-week live online course will make you an expert at building a complete ETL data pipeline on the cloud with tools like Azure, Hive, MongoDB, Spark, Hadoop, etc. The really interesting thing about this program is that you will learn from IIT Guwahati professors and expert professionals at Amazon, Google, Microsoft, etc.
Just gaining theoretical knowledge isn’t enough. You also need to know how to implement your knowledge and solve real business problems. And you can do this by working on data engineering projects and doing internships.
Again, Ivy Professional School’s Data Engineering Certification course helps you work on 30+ real-life projects. This way, you not only gain practical experience but also build an effective portfolio that showcases your skills. Besides, you will earn a valuable certificate from E&ICT Academy, IIT Guwahati, after completing the course. This way, you can become a credible data engineer.
Related: 6 Best Data Engineering Courses
The demand for data engineer roles has increased astronomically. Organizations are actively searching for data engineers to enhance their data processes and ultimately make smart business decisions. The above data engineering skills are in demand, and those who can master these skills will have a good chance of earning high salaries. The question is, will you be one of those?

Prateek Agrawal is the founder and director of Ivy Professional School. He is ranked among the top 20 analytics and data science academicians in India. With over 16 years of experience in consulting and analytics, Prateek has advised more than 50 leading companies worldwide and taught over 7,000 students from top universities like IIT Kharagpur, IIM Kolkata, IIT Delhi, and others.
Team Sep 24, 2022 No Comments
Before a model is created, before the existing data is cleaned and made ready for exploration, even before the responsibilities of a data scientist start – this is where data engineers come into the frame. In this article, we are going to have a look at what is data engineering.
Every data-driven business requires a framework in place for the flow of data science, otherwise, it is a setup for failure. Most people enter the data science niche with the focus of becoming a data scientist, without ever knowing what is data engineering and analytics are and what the role of a data engineer is. They are crucial parts of any data science venture and their demand in the sector is evolving exponentially in the present data-rich scenario.
There is presently no coherent or official path available for data engineers. Most people in this role reach there by learning on the job, rather than abiding by a detailed avenue.
A data engineer is responsible for constructing and maintaining the data frame of a data science project. These engineers have to make sure that there is an uninterrupted flow of data between applications and servers. Some of the responsibilities of a data engineer involve enhancing data foundational procedures, including the latest data management technologies and also software into the prevailing mechanism, and constructing data collection pipelines among various other things.
One of the most crucial skills in data engineering is the potential to design and construct data warehouses. This is where all the raw data is collected, kept, and retrieved. Without data warehouses, all the activities that a data scientist does will become either too pricey or too big to scale.
Extract, Transform, and Load (ETL) are the steps that are followed by a data engineer to construct the data pipelines. ETL is crucially a blueprint for how the assembled data is processed and changed into data ready for the purpose of analysis.
Data engineers usually have an engineering background. Unlike data scientists, there is not much scientific or academic evaluation needed for this role. Engineers or developers who are interested in constructing large-scale frameworks and architecture are ideal for this role.
It is crucial to know the difference between these 2 roles. Broadly speaking, a data scientist formulates models using a combination of statistics, machine learning, mathematics, and domain-based knowledge. He or she has to code and construct these structures using similar tools or languages and also structures that the team supports.
A data engineer on the contrary has to maintain and build data frameworks and architectures for the purpose of data ingestion, processing, and deploying of large-scale data-heavy applications. Construct a pipeline for data storage and collection, funnel the data to the data scientist, to put the structure into production – these are just some of the activities a data engineer has to do.

Now that you know what is data engineering, let us have a look at the roles of a data engineer.

Here are some of the skills that every data engineer should be well versed in.
After this guide on what is data engineering, you must have known that becoming a data engineer is not an easy job. It needs a deep evaluation of tools, technologies, and a solid work ethic to become one. This data engineering job role is presently in huge demand in the industry because of the recent data boom and will prevail to be a rewarding career choice for anyone who is willing to adopt it.
Team Sep 21, 2022 No Comments

Updated on August, 2024
Data science interviews can be scary.
Just imagine sitting across from a panel of serious-looking experts who are here to judge you. Your heart is racing, your palms are sweating, and you start breathing quickly. You can feel it.
It’s normal to feel a little overwhelmed in interviews. But here’s the good news: You can overcome this fear with the right preparation.
In this blog post, I will guide you through the essential steps and useful tips for data science interview preparation. This will help you walk into the room feeling confident and positive.
But before that, let’s first understand this…
The simple answer is data science interviews can be challenging. You need to prepare several different topics like data analysis, statistics and probability, machine learning, deep learning, programming, etc. You may have to revise the whole data science syllabus.
And these technical skills aren’t enough. You also need good communication skills, business understanding, and the ability to explain your work to business stakeholders.
You know the purpose of a data science interview is to test your knowledge, skills, and problem-solving abilities. If you haven’t brushed up on your skills recently, it can be a lot of work. So, let’s start from the beginning…
As I said earlier, preparation is the key to success in data science interviews. And it all starts with a strong foundation that involves:
If you don’t have these, you can join a good course like Ivy Professional School’s Data Science Certification Program made with E&ICT Academy, IIT Guwahati.
It will not only help you learn in-demand skills and work on interesting projects but also prepare for interviews by building a good resume, improving soft skills, practicing mock interviews, etc.
Besides, you will receive an industry-recognized certificate from IIT on completion of the course. This will surely boost your credibility and help you stand out in the interview.
Now, I will share some tips for data science interview preparation that have helped thousands of students secure placements in big MNCs.
These tips will boost your preparation and help you understand how to crack a data science interview like a pro.
This is the first and most important thing to do. Why? Because it will show the interviewer that you are serious about the opportunity. It will also help you provide relevant answers and ask the right questions in the interview.
All you have to do is go to the company’s website and read their About page and blog posts to understand their products, services, customers, values, mission, etc. Also, thoroughly read the job description to understand the key skills and responsibilities.
The goal is to find out how your knowledge and experiences make you a suitable candidate for the role.
Your resume is your first impression. It helps you stand out, catch the interviewer’s attention, and show why you are the right fit for the job. So, you have to make sure it’s good.
What do you mention in your resume? Here are some of the important sections:
Here’s the most important thing: Tailor your resume according to the company’s needs, values, and requirements. That means you should have a different resume for each job application.
What projects you have worked on is one of the most common areas where interviewers focus. That’s because it directly shows how strong a grasp you have over data science skills and whether you can use your skills to solve real-world problems.
So, go through each project you have listed in your data science portfolio. See the code you wrote, the techniques you used, the challenges you faced, and the steps you took to solve the problem. You should be able to explain each project clearly and concisely, from the problem statement to the results you got.
Technical interviews are where the interviewer evaluates whether you have the skills and expertise to perform the job effectively. For this, you need a solid foundation of the latest data science skills.
You should revise all the tools and programming languages like Excel, SQL, Python, Tableau, R, etc., which you have mentioned in your resume. Besides, go through the core concepts like data analysis, data visualization, machine learning, deep learning, etc.
Pro tip: Learn from the data science interview experience of people who have already cracked interviews and secured placements. For instance, this YouTube video shares the experience of one of Ivy Pro’s learners who cracked the interview at NielsenIQ:
I can’t emphasize the importance of this step. Being prepared helps you answer effectively and make a lasting impression.
So, find common questions asked in data science interviews and prepare clear and concise answers. Here are some technical and behavioral questions:
These are just examples. You can do your research or ask professionals in your network to find the most common questions. This will surely make you more confident about your data science interview preparation.
Albert Mehrabian, a professor of Psychology, found that communication is 55% body language, 38% tone of voice, and 7% words only.
So, while your technical skills and experience are important, your body language can make or break your chances of success in the interview.
Here are simple ways to improve your body language:
Your body language shows your confidence and attitude, so try to make it perfect.
Mock interviews can boost your data science interview preparation. It helps you improve your answers and body language, increase confidence, and get used to the scary interview environment.
You can simply practice it with your friends or do it alone by recording yourself while you speak. But the best way to do it is to join a course where they let you practice mock interviews.
For instance, Ivy Pro’s Data Science Course with IIT Guwahati helps you practice mock interviews and learn soft skills. This way, you get feedback to understand your strengths and areas of improvement.
Now, you know how to prepare for a data science interview and crack it with confidence. You need to build a strong foundation in relevant skills, gain hands-on experience, and create a compelling portfolio. Your technical expertise, body language, and attitude are what will help you stand out and land your dream job. So, get started with it. The stronger the preparation, the more your chances of success.
Prateek Agrawal is the founder and director of Ivy Professional School. He is ranked among the top 20 analytics and data science academicians in India. With over 16 years of experience in consulting and analytics, Prateek has advised more than 50 leading companies worldwide and taught over 7,000 students from top universities like IIT Kharagpur, IIM Kolkata, IIT Delhi, and others.