Team Aug 02, 2024 No Comments

You will find numerous data science courses in Kolkata. Some are good, some are just average, and some are exceptionally good.
Choosing the right course is a crucial step. You have to consider factors like course syllabus, faculty expertise, projects and case studies, placement support, etc.
This blog post will help you find the perfect data science institutes and training programs. It lists some of the exceptional data science courses in Kolkata that can help you launch your data career, even if you are a beginner.
With these courses, you can learn in-demand skills, become a certified data scientist, and land high-paying jobs in MNCs. But let’s first understand…
You have to admit data science is a hot career. Currently, the average salary of a data scientist in India is an amazing ₹12,85,000 per year. And if you go to cities like Bangalore, Hyderabad, or Gurgaon, the average salary is around ₹14,00,000 per year. That’s huge, right?
As of June 2024, there are more than 17,000 data science job openings in India at top companies like Google, Microsoft, and Accenture. And things are only getting better with time. The global data science market size is growing with a CAGR of 24.7% and is projected to grow from $133.12 billion in 2024 to $776.86 billion by 2032.
So, if you have the skills and expertise, you will have good pay, job security, and a fulfilling career. You will create a real positive impact by helping businesses and organizations make smart, data-driven decisions. The following data science courses in Kolkata will help you achieve this.
Ivy Pro’s executive data science course is one of the best training programs in Kolkata. Made in partnership with E&ICT Academy, IIT Guwahati, this course helps you become an IIT-certified data scientist.
The live online training lets you join classes from anywhere, interact with instructors, and resolve your doubts instantly. Ivy also offers in-person classes in Kolkata. You will be coached by IIT Guwahati professors and experts from companies like Amazon, Google, and Microsoft.
The course is designed by industry experts and covers essential tools like Excel, Python, SQL, Power BI, Keras, Tensorflow, OpenCV, and Tableau. You will learn in-demand skills like data wrangling, analytics, visualization, machine learning, deep learning, and GenAI.
The course lets you go beyond theoretical knowledge. With 10+ projects, 40+ case studies, and 50+ assignments., you implement your knowledge, create an impressive portfolio, and gain the confidence to solve real business problems.
What’s more, Ivy Professional School helps you develop your soft skills, build your resume, prepare for interviews, and make a social presence. After 45 weeks of training, you become an ideal job candidate for high-paying roles in major tech companies.

Coursera’s IBM Data Science Professional Certificate course series covers skills like data analysis, data visualization, statistical analysis, predictive modeling, machine learning, generative AI, etc.
You will also learn to work with the latest data science tools and libraries like Python, SQL, Pandas, NumPy, Scikit-learn, and Matplotlib. You will be taught by industry experts from IBM who have received high ratings for the quality of their teaching style.
Apart from an updated curriculum, the course covers real-world projects to help learners get practical experience and build a portfolio. It’s an online course that you can easily attend from your home.
You can complete this data science course in Kolkata at your own pace. With 10 hours a week, you can finish it within 6 months. And after completing the course, you will earn a certificate from IBM to boost your credibility as a data scientist.
Simplilearn’s data science course, made in collaboration with IBM, is a suitable option for both freshers and professionals. You get live sessions from industry experts as well as masterclasses from IBM professionals.
This is an online course that you can access from anywhere. It explores basic topics like programming essentials before moving to advanced ones like Python, Tableau, Hadoop, Spark, machine learning, generative AI, etc. You learn useful skills like database management, data analysis, data visualization, large language models, conversational AI, etc.
You will receive a valuable certificate from both Simplilearn and IBM after completing the course. Besides, Simplilearn’s job assist program provides you with career mentoring and helps you land your dream job.
Udemy’s Data Science Course offers comprehensive training covering math, statistics, Python, Tableau, machine learning, deep learning, etc. It’s again an online training that you can access from anywhere in Kolkata.
The course has 31 hours of video, 93 articles, and 541 downloadable resources. Besides, the 137 coding exercises help you apply everything you have learned to real-life situations and gain a deeper understanding.
The program doesn’t require prior experience as it starts from the basics. So, it’s perfect for students who want to launch their data careers. You will learn everything you need to become a data scientist and make your resume strong.
This data science course in Kolkata has got 4.6/5 ratings from over 140,000 learners on Udemy. So, it’s a good one.
Massachusetts Institute of Technology’s Applied Data Science Program is a reputed course that is taught by highly experienced MIT faculty. This is a 12-week live online training, so you can attend it from anywhere in Kolkata and interact with instructors.
You will learn how to leverage AI to make data-driven decisions. The course covers in-depth topics like machine learning, deep learning, recommendation systems, ChatGPT, applied data science with Python, generative AI, etc. You learn tools like Python, NumPy, Keras, TensorFlow, etc.
You also work on 6 projects under the guidance of industry experts to gain hands-on experience and solve business problems. You also get live mentorship from data science practitioners on weekends to gain more clarity.
Finally, you will earn a professional certificate from MIT upon completion of the course.
Ivy Professional School stands out as the best data science training institute in Kolkata for several reasons. Since 2008, Ivy Pro has been a top-ranking data science, analytics, and AI education provider. This success is due to its unmatched course quality and smart teaching approach.
Ivy Pro has the top 1% faculty, with instructors who bring decades of industry experience and know how to make learning engaging and memorable. Besides, learners also get mentored by experts from prestigious institutions like IIT and companies like Amazon, Google, and Microsoft.
The course curriculum is designed to meet industry standards and includes practical training on essential tools like Python, SQL, and Tableau. Students work on real-world projects, gaining hands-on experience to solve real business problems.
The institute also collaborates with prestigious organizations like IIT Guwahati, IBM, and NASSCOM to ensure its programs are up-to-date and effective. No wonder that Fortune 500 companies like Tata Steel, Accenture, ITC, Cognizant, and Capgemini trust Ivy Pro’s training and actively recruit Ivy Pro graduates.
In the last 16 years, Ivy Professional School has helped over 29,500 learners get placed in more than 400 organizations. If you want to become the next success story, you can join Ivy Pro’s IIT-certified data science course and achieve your career goals.

Becoming a data science expert isn’t that easy. You will need a comprehensive syllabus and experienced mentors. We have listed some of the best data science courses in Kolkata. Go through their course pages carefully to decide which one best meets your requirements. After all, choosing the right course can significantly impact your career, giving you the skills to become a competitive job candidate.

Prateek Agrawal is the founder and director of Ivy Professional School. He is ranked among the top 20 analytics and data science academicians in India. With over 16 years of experience in consulting and analytics, Prateek has advised more than 50 leading companies worldwide and taught over 7,000 students from top universities like IIT Kharagpur, IIM Kolkata, IIT Delhi, and others.
Team Jun 07, 2024 No Comments

Updated on 9th August, 2024
Want to be a data scientist? Well, it’s a promising career choice with good job opportunities. As a skilled data scientist, you can expect a good salary, job security, work satisfaction, and, ultimately, a chance to create a real impact in the world.
But where do you start? What should you study? Which institute should you join?
Don’t worry, I have got you covered. In this blog post, I am going to share a list of the 5 best institutes for data science in India. We will take a quick look at what makes each one unique so you can choose the best fit for you. But, let’s first see…
Different institutes have different syllabi for their data science courses. Before you choose an institute, you must go through the syllabus to make sure it’s updated and relevant to present industry needs. To give you an example, here is the latest, industry-relevant syllabus followed by Ivy Professional School in its Data Science and AI Certification course.
Here are some of the best data science institutes you can choose for mastering this high-income skill in India:
Ivy Professional School has been a top-ranked data science, data analytics, and AI upskilling provider since 2008. Ivy offers the Executive Data Science and AI Certification course in partnership with E&ICT Academy, IIT Guwahati.
In this program, you get mentored by IIT professors and experts from Amazon, Google, Microsoft, etc. You learn skills like data analytics, visualization, ML, Cloud, AI, GenAI, etc. Apart from learning industry-relevant skills, this 45-week course helps you complete 50+ real-world projects and build an impressive portfolio. The live online classes and live doubt-clearing sessions help you build solid foundations.
You also get placement assistance that helps you with your CV and interviews. All this helps you land high-paying data science jobs in top MNCs. No wonder Ivy is at the top of the list of the best institutes for data science.
IIT Madras is a premier institute known for its excellence in engineering and applied sciences. This institute offers a 4-year Bachelor of Science degree in Data Science and Applications. This is a hybrid course with pre-recorded sessions, weekly online assignments, and in-person quizzes.
This course is good for both students and working professionals, and it will help you learn ML foundations, deep learning, computer vision, large language models, big data, etc. For admission, you have to apply for an in-built qualifier process in which you will be taught for 4 weeks and then asked to qualify for an admission exam.
One of the best institutes to learn data science, IIM Calcutta is a prestigious business school recognized for its flagship MBA programs. It offers the Advanced Programme in Data Sciences (APDS) that helps students learn various tools and techniques for managing, analyzing, and interpreting data. The course covers tools like Tableau, Python, R, SPSS Modeler, etc.
This course is best for working professionals and young managers who want to learn real-world data science skills. This one-year course is conducted in the form of 3-hour online sessions every Sunday. To apply for this course, you must be a working manager with 3+ years of experience or a graduate/postgraduate in any discipline with 50% marks.
Scaler is an ed-tech platform that helps techies upskill with its various courses. It offers a Data Science and Machine Learning program that helps you learn essential skills to succeed in the field. This online program, which runs for 11 to 15 months, focuses on tools like Git, TensorFlow, PySpark, PyTorch, Kafka, Hive, etc.
With 1:1 mentorship, focus on projects and case studies, and career counseling, Scaler ensures you become an expert at solving problems and making smart business decisions. The course is best for freshers and working professionals who have a good understanding of languages like Python or have a degree in maths, engineering, or statistics.
IIT Delhi is one of the best technical institutes in India, and it is recognized for its research and innovation. The institute offers the Advanced Certificate in Data Science and Decision Science course. It focuses on skills related to data handling, analytics, cognitive sciences, various data science tools, etc.
This is a live online program that spans a total of 12 months, providing 150 hours of teaching. The program is best for professionals and leaders who want in-depth knowledge of decision-making with data. Selection for this course is done by reviewing applications and conducting personal interviews.
And there you have it! A glimpse into some of the best institutes for data science out there. Hopefully, this gives you a starting point to explore which program best aligns with your goals, learning style, and budget.
If you are looking for the top data science institute, you can go for Ivy Professional School. Ivy has over 29,000+ alumni who are working in leading roles in 400+ organizations. Apart from expert faculty, Ivy partners with IIT Guwahati, IBM, and NASSCOM to deliver top-notch learning programs.
Whether you are a student or working professional, Ivy can help you learn in-demand data science skills, complete capstone projects, get practical experience, build your portfolio and resume, prepare for interviews, network with alums, and finally get your dream job.
Visit this page to learn more about Ivy’s Data Science and AI course.
Is data science a well-paying job?
Yes, data science is a well-paying job. Skilled data scientists are in high demand, and companies are willing to offer competitive salaries to attract top talent. In India, the average salary of a data scientist is ₹13,00,000 per year. Senior data scientists with 2-4 years of experience can even earn between ₹17 lakhs to ₹30 lakhs per year. That’s a huge number, right?
What’s the best data science institute in India?
There are many great data science institutes in India, but Ivy Pro School stands out for its comprehensive courses, experienced faculty, and strong track record of student success. Since 2008, Ivy Pro has been a top-ranking data science, AI, and data analytics upskilling provider. This institute helps you work on real-world projects, ensures your holistic development, and gives you lifetime placement support so that you have a bright career.
Is data science a stressful job?
It depends on you. If you love playing with numbers and solving real business problems with data, you may not feel that much stress. However, as it happens in most jobs, there can be pressure to meet deadlines and deliver results. Or you may get stuck in an error for days. But if you love the job and like to face challenges, you will enjoy it.
Which city is best for data science in India?
Cities like Bangalore, Hyderabad, Gurgaon, and Mumbai are well-known for their tech industries and offer many opportunities in data science. Kolkata is also emerging as a strong hub for data science education and jobs, especially with top institutes like Ivy Pro School providing quality training.
Is data science still in demand in 2024?
Absolutely! Data science continues to be in high demand in 2024, and it will only get bigger with time. For instance, the global data science market is projected to expand from $133.12 billion in 2024 to $776.86 billion by 2032. So, the need for skilled data scientists is going to increase in the coming days.
Which college has the best placement for data science?
Several colleges in India offer good placements for data science. The above blog post talks about such institutes in detail. Ivy Professional School is one such institute that has helped over 29,500 learners get placed in some of the biggest companies like Honeywell, Samsung, PWC, IBM, HSBC, Amazon, Cognizant, etc. Ivy Pro has strong industry connections and provides lifetime placement assistance, making it easier for students to land jobs.

Eeshani Agrawal holds an MS in Civil Engineering from Texas A&M University (USA) and has over 16 years of experience in data visualization, storytelling, and analytics. She has consulted for top engineering, manufacturing, and consulting firms worldwide and has coached over 9,000 professionals and students from leading institutions like IITs, IIMs, and ISI.
Team May 27, 2024 No Comments

You want to become a data engineer? That’s a smart choice because data engineers are in high demand right now.
And they earn impressive salaries. In fact, the average annual salary for a data engineer is ₹11,00,000 in India (Glassdoor).
But how do you break into this promising field? Well, you need a solid foundation. And that starts with an effective, up-to-date data engineering syllabus.
The syllabus is the roadmap that guides you through the essential skills and knowledge you need to land your dream job. Since technology is rapidly evolving, you need a relevant curriculum that focuses on the latest tools, techniques, and best practices.
In this blog post, we will explore the latest data engineering course syllabus. This will help you understand what you need to study and what skills you should develop in 2024 to step into this promising career path.
Data engineering is the field of study that involves building and maintaining data systems that collect, store, and manage data in an organization. This field is a mix of software engineering, database administration, and data science skills.
Data engineers ensure that the right data flows seamlessly from various sources into a centralized location like a data warehouse. This becomes possible because of the designing and implementing of data pipelines that extract, transform, and load (ETL) data from databases, APIs, sensors, and other sources.
Data engineers are also responsible for ensuring the quality and reliability of data. This involves cleaning and validating data, handling missing values, and addressing inconsistencies. They also implement data governance policies to ensure data privacy, security, and compliance with regulations.
Data engineers work closely with data scientists and analysts to understand their needs and design data models that are optimized for analysis and reporting. They may also develop custom tools and applications to streamline data workflows and automate repetitive tasks.
This way, data engineers play a crucial role in helping organizations utilize the power of data and gain a competitive edge in today’s fast-changing market. Now that you understand the basics of data engineering, let’s move on to the next section…
Here is the latest data engineering course syllabus. It is divided into four major sections focusing on four primary topics- SQL, Python, Big Data Processing, and Azure Cloud Engineering.
The following industry-relevant syllabus is strictly followed in the Data Engineering Certification course by Ivy Pro School, which is made in partnership with E&ICT Academy IIT, Guwahati.
If you want to learn data engineering and gain practical skills, you can join the course. It’s a live online program, so you can learn from anywhere. We will talk more about the course later. Let’s see the syllabus first:

Here’s an overview of the SQL for Data Engineering section:
This section of the data engineering syllabus provides students with a comprehensive understanding of SQL, from basic to advanced levels.
It begins with foundational SQL queries, including SELECT statements, filtering, and sorting data. Students also learn to clean and modify data, covering essential operations like updating, transforming, and deleting data while handling errors and validating results.
The course then progresses to more complex topics such as data aggregation, advanced data filtering with pattern matching, and the use of window functions.
Next, students explore working with multiple data tables through various JOIN operations and conditional logic with CASE statements.
Advanced topics include creating and managing databases with DDL statements and developing user-defined functions and stored procedures to automate SQL operations.
Throughout the section, students engage in hands-on exercises and case studies using real-world datasets from industries like eCommerce and retail to apply their SQL skills.
Here’s an overview of what happens in the Python Essentials for Data Engineering section:
The second section of the data engineering syllabus introduces students to Python programming, with a focus on its application in data engineering tasks. Starting with the basics, students learn about Python’s data types, variables, and basic operations.
The course then steps into data structures such as lists, dictionaries, and tuples and shows how to manipulate them using Python’s powerful libraries, particularly Pandas. Students are taught to write and use functions and modules, enabling them to create reusable code.
A significant part of the section is dedicated to data wrangling with Pandas, where learners practice creating, cleaning, transforming, and aggregating data within DataFrames.
Additionally, the course covers API interactions, allowing students to fetch and process data from web APIs and database connectivity using SQLAlchemy to perform CRUD operations.
Error handling and debugging are also emphasized, ensuring students can identify and resolve common issues. And finally, hands-on projects throughout the section help solidify these skills.
Here’s what happens in the third section of the data engineering syllabus:
The Big Data Processing section offers a comprehensive overview of big data technologies and their applications in data engineering. The course begins with an introduction to the fundamental concepts of big data and explores key technologies such as Hadoop, Apache Hive, and Apache Spark.
Then, students learn about the Hadoop ecosystem, including HDFS and MapReduce, and gain practical experience in data storage and processing using Hadoop.
The course then covers Apache Hive, teaching students to query large datasets using HiveQL and apply these skills in hands-on projects.
Apache Spark is introduced next, with a focus on its architecture, RDDs, and DataFrames, and students learn to process data in real-time using Spark. The section also addresses data ingestion and storage techniques, highlighting the use of NoSQL databases like MongoDB.
In the final section, students explore real-time data processing with Kafka and its integration with Spark. They complete practical projects that emphasize building and managing real-time data pipelines.
Here’s what happens in this fourth and final section of the data engineering syllabus:
The Azure Cloud Engineering section provides an in-depth understanding of Microsoft Azure and its application in data engineering.
Students begin with the fundamentals of Azure, including an overview of its services, infrastructure, and security concepts such as Azure Active Directory and role-based access control.
The course covers the creation and management of Azure virtual machines, along with the use of Azure storage services like Blob, Queue, and Table for efficient data storage and retrieval.
Advanced topics include building end-to-end data pipelines with Azure Data Factory, which involves data movement, transformation, and integration, and an introduction to Azure Databricks for collaborative data processing.
Real-time data streaming is also covered, focusing on Azure Event Hubs and its integration with Azure Data Factory.
The section addresses hybrid cloud scenarios, teaches students to manage data workloads across on-premises and multi-cloud environments, and emphasizes governance and compliance standards.
Practical, hands-on projects throughout the section ensure students learn to apply their knowledge in real-world settings.
If you want to become a skilled data engineer, you can join Ivy’s certification course. This course follows the exact same data engineering syllabus as above and is developed in partnership with the prestigious E&ICT Academy IIT Guwahati.
Here is why you should choose Ivy’s Cloud Data Engineering course?
The course helps you become job-ready in just 45 weeks. Interested in learning more? Visit our Data Engineering course page for a detailed syllabus and enrollment information.
Is data engineering more difficult than data science?
It depends on your skills, experience, and strengths. Data engineering requires strong programming skills to build data pipelines, handle large amounts of data, and ensure data quality. Data science requires proficiency in statistics, machine learning, data visualization, and communication to find valuable insights from data and convey them easily. You can research and network with professionals in both domains to gain a better understanding.
Can you be a data engineer without coding?
No, you can’t become a skilled data engineer without strong coding skills. Your job as a data engineer involves building data extraction, transformation, and loading systems, working with data pipelines, managing data, and debugging and troubleshooting data systems. All of these require programming skills. That’s why Ivy Pro’s IIT-certified Data Engineering course teaches all the essential coding languages for data engineers.
Which coding languages are best for data engineers?
Python, SQL, Java, R, and Scala are some of the top programming languages used by data engineers. You will also need proficiency in tools like Apache Spark, Hadoop, and ETL frameworks. No matter which language you use, you will need a good understanding of data structures and algorithms.
Is Python enough for a data engineer?
No, Python is not enough. Python is an essential language for data engineers, and it can help you with data manipulation and data analysis. However, you will also need to learn data warehousing concepts, SQL, big data technologies like Hadoop, Spark, and Hive, and cloud platforms like AWS.
Is Java good for data engineering?
Yes, Java is a good language for data engineering. Since it’s an object-oriented programming language, it helps you write code that is easy to read, reuse, and maintain, helping you easily build complex data systems. Besides, Java has excellent performance, wide adoption, numerous libraries, and a supportive community.
Prateek Agrawal is the founder and director of Ivy Professional School. He is ranked among the top 20 analytics and data science academicians in India. With over 16 years of experience in consulting and analytics, Prateek has advised more than 50 leading companies worldwide and taught over 7,000 students from top universities like IIT Kharagpur, IIM Kolkata, IIT Delhi, and others.
Team May 15, 2024 No Comments

Data engineers collect, organize, and store raw data. This helps companies uncover valuable insights, improve their products, and better target their marketing. That’s why companies value data engineers.
But is data engineering a good career? Are data engineers in high demand?
There’s actually a high demand for skilled data engineers, and the job offers a competitive salary and good learning opportunities.
If you see the numbers, the global big data and data engineering market is projected to grow from USD 51.7 billion in 2022 to USD 140.80 billion in 2028. So, you can also expect good job security.
Keep reading to find out more. We will explore what data engineers do, why this career path is worth pursuing, and what the future of data engineering is. So, here we go…
Data engineers are the plumbers of the data world, building pipelines that collect data. They extract raw data from different sources and store it in a usable format.
Data engineering is all about making data available, consistent, secure, and recoverable for an organization. For this, they have to build and maintain infrastructures like databases, big data repositories, and data pipelines.
Here’s a breakdown of their key tasks:
As a data engineer, you will often collaborate with data analysts and scientists to ensure data matches their needs and the organization achieves its goals. And that’s how you will be playing a critical role in helping businesses make data-driven decisions.
Here are some key data engineering skills:
SQL: You need to learn SQL queries and operations like data cleaning, aggregation, and error handling, as well as advanced SQL features like subqueries and user-defined functions.
Python: Python programming is essential. You need to learn Python basics, advanced data structures, functions for data preprocessing, data wrangling, debugging, etc. Besides Python, you can also learn programming languages like Java, R, and Scala.
Data Warehouses: A data warehouse is a data management system that stores large amounts of data from various sources in an organized way. You need to know how to design, build, and manage it so that businesses can carry out their BI, analytics, and reporting smoothly.
ETL Pipelines: ETL stands for Extract, Transform, and Load. It helps businesses collect, store, and use data efficiently. This involves taking raw data from various sources, cleaning it up, and then loading it into a single system for further use.
Big Data Processing: This helps you work with large amounts of data. You need to learn the fundamentals of big data and key technologies such as Hadoop, Apache Hive, and Apache Spark. You can work on projects that involve building and managing real-time data pipelines.
AWS, Google Cloud, Microsoft Azure: Cloud services are used to store and manage data over the internet, so you don’t need physical servers. AWS, Google Cloud, and Azure are technologies that allow you to do this. Simply gaining an in-depth understanding of Microsoft Azure and its application in data engineering would be enough.
Read this post to know more about the latest data engineering syllabus and skills.
You also need to develop certain soft skills to work smoothly in the corporate world.
The most important is communication skills, which are necessary to clearly explain technical details to non-technical colleagues and stakeholders. Good communication also helps you better understand the problems of your clients and get relevant feedback to deliver the best work.
You also need attention to detail, problem-solving skills, presentation skills, and the ability to work well in a team.
And obviously, to get a job, you need to know how to perform well in interviews. That’s why we at Ivy Professional School help our students by letting them participate in mock interviews.
So, now you understand that data engineers build the foundation for data-driven decision-making for organizations and what skills they need to do it. But does that mean it’s a good career path for you?
Well, let’s see some of the reasons why data engineering is an attractive career path:
High Demand: Businesses have to deal with massive amounts of data. This creates a constant need for skilled data engineers to collect and manage it. That’s why, in April 2024, there were over 10,500 job openings for data engineers across all industries on online job portals in India.
Impressive Salaries: With high demand comes high pay. Data engineers typically earn competitive salaries because of the value they bring to organizations. The average base pay of data engineers in India is ₹9,41,500 per year. And senior data engineers with 2-4 years of experience have an annual average base pay of ₹18,50,000.
Learning Opportunity: Data engineering requires creativity and problem-solving. You will constantly be challenged to design new data pipelines, clean up raw data, and find innovative ways to make data usable. This means you will get to learn a lot of tech and soft skills.
Creating Impact: You will work on a variety of projects across different industries, making a real impact on how businesses operate and make decisions.
Job Security: According to IDC, the global datasphere is projected to reach a staggering 175 zettabytes by 2025. This ever-increasing data volume creates a constant demand for skilled data engineers. That’s why data engineer jobs are expected to grow at a rate of 21% from 2018-2028 in the US. This means you can have a stable and rewarding career.

The above points make data engineering an irresistible career path. However, there are also certain challenges that you must take care of. Here they are:
Now, you will be able to judge if data engineering is for you or not. Let’s move on to the next section for an even better understanding…
First of all, it’s important to consider if this career aligns with your interests and skills.
If you like programming, are passionate about data, and love challenges, then the benefits of data engineering can outweigh the challenges.
However, you will need a learning attitude. The market is ever-changing, so a love for continuous learning is essential to stay relevant in this field.
You will also need communication and teamwork skills. Because data engineers often work with data scientists, analysts, and other professionals to help an organization achieve its goals.
If you match the above requirements, data engineering will be a rewarding career path for you that will offer good pay, job security, and the chance to make a real impact in the world.
The world of data is constantly growing. And you, as a data engineer, will continue to play a vital role in shaping its future. Here are some exciting trends to look forward to:
With the ever-growing importance of data, data engineers will be even more crucial for businesses of all sizes. If you are looking for a promising career, you can definitely consider data engineering.

If you want to learn data engineering, you can join Ivy’s Cloud Data Engineering Certification course.
This is an online course made in partnership with E&ICT Academy IIT Guwahati. So, you will be coached by IIT Guwahati professors as well as experts from Amazon, Google, Microsoft, etc.
The course will help you learn current industry skills, complete 30+ real-life projects, and become job-ready in just 45 weeks.
And this program is perfect for both college graduates as well as working professionals who want to upskill. Visit this page to learn more about Ivy’s Cloud Data Engineering course.
Is data engineering a good career in India?
Yes, data engineering is a promising career in India. With impressive salaries, job security, and a lot of learning opportunities, data engineering can help you achieve your career goals. And since the global big data and data engineering market is expected to grow from $51.7 billion in 2022 to $140.80 billion in 2028, you can expect the demand for data engineers will only grow with time.
Are data engineers in high demand?
Since data-driven decision-making has become a necessity, data engineers are in high demand. Companies across various industries need them to build and maintain the infrastructure needed for data collection, storage, processing, and analysis. That’s evident from the fact that data engineering jobs are expected to increase at a rate of 21% from 2018-2028 in the US.
Does data engineering involve a lot of coding?
Yes, data engineering involves a lot of coding. Data engineers use programming languages like Python, SQL, Scala, and Java to build data pipelines, manage databases, and make sure data is processed efficiently. If you want to be a skilled data engineer, you have to master the above programming languages, which you can easily do by taking online data engineering certification courses.
Do data engineers make good money?
The average salary for a data engineer in India is ₹8,53,500 per year. Location, industry, company size, and years of experience are some factors that can influence the salary. For instance, data engineers in Bangalore earn an average annual salary of ₹11 lakhs, and in Pune, it is ₹9 lakhs. But whatever the case, as the demand for data engineers continues to rise, salaries are expected to remain high.
Who gets paid more: software engineers or data engineers?
Both software engineers and data engineers are well-paid, but their salaries can vary based on factors like company, location, experience, etc. If you compare the average annual salary, data engineers earn ₹8,53,500, and software engineers earn ₹8,21,152, according to Glassdoor. So, data engineers can earn slightly more due to their specialized skills and the growing necessity of data-driven decision-making.
Is data engineering a stressful job?
The right answer depends on you and the company you will work at. However, like most technical jobs, data engineering can be challenging at times, especially when dealing with complex data systems or tight deadlines. The thing is, you have to ensure that data systems are efficient, reliable, and secure. Which can be stressful. But if you have mastered the skills, have good experience in solving data-related problems, and love programming, the work can be very rewarding.
Will AI replace data engineers?
Okay, that’s a hot question. AI can automate repetitive and laborious tasks like data ETL, data integration, data pipeline creation, etc. But it won’t fully replace data engineers. Skilled data engineers will be needed to perform those complex tasks requiring human expertise and creativity. So, keep improving your skills, stay updated with the industry, and learn to utilize AI. AI is your co-pilot, which can boost your efficiency and problem-solving ability.
Eeshani Agrawal holds an MS in Civil Engineering from Texas A&M University (USA) and has over 16 years of experience in data visualization, storytelling, and analytics. She has consulted for top engineering, manufacturing, and consulting firms worldwide and has coached over 9,000 professionals and students from leading institutions like IITs, IIMs, and ISI.
Team May 06, 2024 No Comments

Mastering data science requires constant learning. Books can help you learn new things, improve your techniques, and change how you approach problems.
No matter whether you are an aspiring data scientist or a professional, reading data science books lets you effectively transform raw data into powerful insights and tell better stories.
To help you on this journey, in this post, we have shared some of the best data science books you must read. So, get ready to become smarter and more skilled.
Here are some of the best books for data scientists that will help you sharpen your skills. They will improve your problem-solving ability and help you use data to make sense of this confusing world:
Author: Joel Grus is a research engineer at the Allen Institute for Artificial Intelligence. Formerly a software engineer at Google and a data scientist at numerous startups.
About: This is one of the best data science books for beginners that goes beyond using basic tools. The book covers data manipulation, machine learning models, and even advanced topics like recommendation systems and natural language processing. You will gain a strong foundation in the math and statistics behind data science, plus the coding skills to put it into practice.
Get the book: Data Science from Scratch
Authors: It’s written by famous data science experts Foster Provost and Tom Fawcett. Provost is a Professor of Data Science at New York University’s Stern School of Business. And Fawcett is a machine learning Ph.D. holder who has worked in industry R&D for over 20 years.
About: This book teaches you the core concepts of data science and how to apply them to solve real business problems. The book emphasizes “data-analytic thinking” to help you extract valuable insights from data. It’s ideal for those wanting to bridge the gap between data science and its practical business applications.
Get the book: Data Science for Business
Author: Wes McKinney is an American software developer, Co-founder of Voltron Data, and creator of the Python pandas project. He studied theoretical mathematics at MIT and graduated in 2006.
About: This data science book teaches you essential Python skills for working with data. You will learn data cleaning, manipulation, and analysis to effectively solve diverse sets of data analysis problems. This book is packed with practical case studies and is perfect if you are new to Python and want to get introduced to scientific computing in Python.
Get the book: Python for Data Analysis
Authors: It’s written by Peter Bruce and Andrew Bruce. Peter Bruce is the founder of the Institute for Statistics Education at Statistics.com. Andrew Bruce is a Ph.D. holder in statistics at the University of Washington and has 30+ years of experience in statistics and data science.
About: This book bridges the gap between traditional statistics and how it’s used in data science. It covers essential statistical methods, shows how to apply them correctly, and helps you avoid common mistakes. You will learn about exploratory analysis, sampling, experimental design, regression, classification, and even machine learning from a statistical viewpoint.
Get the book: Practical Statistics for Data Scientists
Author: Cole Nussbaumer Knaflic is the founder and CEO of Storytelling With Data. She has been analyzing data and telling compelling stories for the last 10 years.
About: “Storytelling with Data” is a must-read book for data scientists. It teaches you how to transform data into clear and compelling visuals that tell an informative story. You will learn the principles of effective data visualization and how to go beyond basic charts to create presentations that engage your audience. If you want to make your data analysis truly impactful, this book is for you.
Get the book: Storytelling with Data
Authors: It’s written by Hadley Wickham and Garrett Grolemund.
Hadley, renowned for his contributions to R, serves as chief scientist at Posit, PBC, and is an adjunct professor at the University of Auckland, Stanford, and Rice University.
Garrett, a Ph.D. holder in statistics from Rice University, serves as the director and developer relations at Posit, PBC.
About: This is a beginner-friendly guide suitable for people who have no previous programming experience. It teaches you R, RStudio, the tidyverse (a set of helpful packages), and the entire data science process. You will learn data cleaning, exploration, modeling, and how to present your results effectively. The book has a lot of exercises that will help you apply your knowledge to solve problems.
Get the book: R for Data Science
Authors: Andreas C. Müller and Sarah Guido wrote this data science book. Andreas Müller, PhD holder in machine learning from the University of Bonn, works at the Center for Data Science at the New York University. Sarah, a data scientist residing in New York City, worked in many startups.
About: This book is a practical guide to building machine-learning applications using Python. The book focuses less on the maths and more on the practical side of using ML algorithms, making it a beginner-friendly book. Apart from the Scikit-learn library, you will also get familiar with NumPy and Matplotlib libraries.
Get the book: Introduction to Machine Learning with Python
Author: Seth Stephens-Davidowitz is a data scientist, economist, and author. Formerly a Google data scientist and a visiting lecturer at the Wharton School of the University of Pennsylvania.
About: This is one of the best books for data scientists who want to understand the application of data science. “Everybody Lies” explores how big data can help us uncover hidden patterns about how people think and behave. The book teaches you to analyze large datasets to answer interesting questions about the world, covering topics like prejudice, decision-making, and even the impact of movies on crime. Aspiring data scientists will learn to think critically about data and see how it can be used to challenge common beliefs.
Get the book: Everybody Lies
Data science books are good for sharpening skills. But if you want to build a strong foundation and gain real-world experience, Ivy’s Data Science and AI certification course can help you.
This online course is made in partnership with E&ICT Academy IIT Guwahati, so you will be coached by IIT professors and will get an IIT-branded certificate upon completion of the course.
This online course will teach you in-demand skills like data analytics, ML, Gen AI, deep learning, etc., with tools like Adv Excel, SQL, Python, Power BI, VBA, Tensorflow, etc.
With 50+ real-life projects, live doubt-clearing sessions, and placement assistance for holistic growth, the course makes you job-ready in 45 weeks. Visit this page to learn more about Ivy’s Data Science and AI course.
Team Apr 29, 2024 No Comments

“What’s the data scientist’s salary in India?” Aspiring data scientists often ask this question.
You see, the data science field is constantly in demand. It combines coding, math, and business skills to uncover valuable insights from massive datasets and help businesses make smart decisions.
But if you are considering a career in this field, you might be curious how much it can pay you. After all, we all need strong reasons to jump into a career path.
In this blog post, you will know the salaries of data scientists in India and in major Indian cities. This will surely inspire you to learn and upskill to become an expert data scientist and get impressive paychecks.
And, if you actually want to learn data science, you can enroll in Ivy Pro School’s Data Science and AI Certification course in partnership with E&ICT Academy, IIT Guwahati. This solid online course will make you job-ready in just 45 weeks.
The salary of data scientists in India is affected by several factors. But before we get into the details, here’s a general figure:
Average Salary: The average salary of data scientists in India is ₹13.5 lakhs per year (Glassdoor). This salary varies within the range of ₹8 lakhs to ₹19 lakhs per year.
Starting Salary: The starting salary of data scientists in India with less than one year of experience is ₹6 lakhs per year, including tips, bonuses, and overtime pay (Payscale).
Early Career Salary: The average salary of data scientists with 1-4 years of experience is ₹9 lakhs per year. Whereas the average salary of data scientists with 5-9 years of experience is ₹15 lakhs per year (Payscale).
Senior Career Salary: A senior data scientist with 10-19 years of experience earns an average salary of ₹21 lakhs per year. Glassdoor says that a senior data scientist with over 8 years of experience can earn in a range of ₹25 lakhs to ₹52 lakhs per year.

Here are some of the key factors influencing how much data scientists earn in India (there may be exceptions):
Experience: It’s what happens in most jobs – the more experienced you are, the more you are likely to earn. Freshers start at the lower end, while highly experienced data scientists with specialized skills get really handsome paychecks, some even reaching an astounding ₹52 lakhs per year (Glassdoor).
Location: Tech hubs like Bangalore, Mumbai, and Delhi usually offer better salaries compared to smaller cities due to a higher demand for data scientists and a higher cost of living. We will see the average salary of data scientists in those Indian cities in the following sections.
Industry: Some industries, like finance and e-commerce, really value data-driven insights. They’re prepared to pay more for skilled data scientists. For instance, the average annual salary of data scientists in financial services in India is ₹15.3 Lakhs (AmbitionBox).
Company Size: Generally, big-name companies and multinational corporations offer more competitive salaries and benefits packages than smaller startups. For instance, a data scientist at IBM earns an average base salary of ₹14.5 lakhs per year (Glassdoor).
So, now you realize data scientists really make big money. But there is a reason why they are paid so much. Actually, if you want to enter this field, you will be more motivated by the impact you create than the money you make. This brings us to the next section:
Here are the primary reasons why data science is one of the top 10 highest-paying jobs in the world:
Businesses Need to Understand Data: By 2025, it’s estimated the world will create roughly 463 exabytes of data daily. Businesses collect these datasets, which can be about customer behavior, market trends, machines, etc., to find valuable insights. But that data means nothing unless they can understand it. Data scientists have the skills to transform raw data into actionable insights that help companies make better decisions.
Data Scientists have Unique Skill Set: Data science is a mix of technical and business skills. Data scientists need to know not only statistics and programming but also problem-solving and communication. They also need to understand business problems and how to translate data into solutions. That’s what makes them valuable.
High Demand, Low Supply: There’s a lot more data out there than data scientists can handle. Businesses across industries are eager to find data-driven insights, but finding qualified data scientists remains a challenge. Businesses have to utilize data to survive in the market, or their competitors will win. This necessity and shortage of good data scientists drive up salaries as companies compete for top talents.
So, the thing is, companies need good data scientists. Because they rely on data-driven insights to optimize pricing, target advertising, predict customer churn, streamline logistics, and perform countless other business processes. That’s why they are willing to pay so much to skilled professionals. Now, let’s move on to the next section…
Here are some of the Indian cities that pay data scientists the most with the average salary they offer. This will help you choose the right city for jobs and make your career a fulfilling journey.

Delhi has tons of jobs for data scientists, including various sub-domains like ML, AI, and data analytics. You will find big companies, new startups, and even government projects that need skilled professionals. The average salary of data scientists in Delhi is ₹15 lakhs per year. Apart from this, you will love the delicious street food and local markets like Chandni Chowk and Sarojini Nagar.
One of the most rapidly developing cities, Gurgaon, is a favorable environment for data scientists with a significant number of job opportunities. Many multinational companies and international startups have offices there, so you will find good jobs with good pay. It’s modern and close to everything Delhi has to offer. And the average salary of data scientists in Gurgaon is ₹17 lakhs per year.
Mumbai offers a vibrant landscape for data scientists. There are multinational companies, tech firms, and startups with new data scientist positions being added daily. It’s a busy, exciting city where you can meet ambitious people. The average salary of data scientists in Mumbai is ₹16.5 lakhs per year. And in this city of dreams, you will like to spend peaceful time near the beaches and have luxurious dinners in 5-star restaurants.
Bangalore is a hotspot for data science professionals, with over 39,000 data scientist jobs. These job openings are for various domains within data science, like junior data scientists, Python developers, machine learning engineers, and data science specialists. The average salary of data scientists in Bangalore is ₹17 lakhs per year. The city offers a professional environment, with most people working in corporations. And you are certainly going to love the pleasant weather here.
Hyderabad offers thousands of data scientist jobs, with new job openings being added regularly. There are big companies and smaller startups, so you have choices of where you want to work. The average salary of data scientists in Hyderabad is ₹12 lakhs per year. It’s a more relaxed city than some of the biggest ones, so you can expect a peaceful time here. And did we mention the delicious Hyderabadi biryani?

Now that you know the data scientist’s salary in India, you must be feeling excited to enter this field.
So, if you want to learn and become a skilled data scientist, you can join Ivy Pro School’s Data Science and AI Certification course in partnership with E&ICT Academy IIT Guwahati.
This course teaches you all the industry-relevant skills like ML, AI, Cloud, Gen AI, Data Analytics, Data Visualization, etc., with tools like Adv Excel, SQL, Python, Power BI, VBA, Tensorflow, etc.
In this 45 weeks of training, you will be coached by professors from IIT and experts from Amazon, Google, Microsoft, etc, making you ready for high-paying data science jobs.
Visit this page to learn more about Ivy’s Data Science and AI Certification course.
Team Apr 23, 2024 No Comments

Data science is a very attractive career choice now. It offers excellent salaries, incredible work satisfaction, good job security, and a chance to make this world a better place.
No wonder the Bureau of Labor Statistics projects 35.2% employment growth for data scientists between 2022 and 2032.
If you want to enter this thriving field, the beginning steps can be confusing. What should you learn? What’s the syllabus of data science courses? What subjects do you need to master? All these are common questions you may have.
This blog post is here to help. We will share an updated data science course syllabus and subjects, giving you a roadmap to success. But first, let’s understand the role of data scientists and why they matter so much.
Data scientists basically find hidden patterns and insights in raw data. This helps businesses avoid guesswork and make informed decisions.
A McKinsey study found that data-driven companies are 23 times more likely to acquire customers, 6 times as likely to retain them, and 19 times as likely to be profitable. This shows why businesses are dying to hire good data scientists.
Data scientists also help businesses understand why a certain thing happened and predict what might happen in the future.
For instance, if a business finds its sales are dropping, a data scientist can help understand the cause behind it. To do this, they collect relevant data like sales numbers, website visits, customer surveys, etc. Then, they clean the data to make it organized.
Next, they use data analytics tools to analyze the data and find insights. They also use Machine Learning to examine massive data sets automatically, without any human involvement.
Finally, they communicate their findings to the business’s decision-makers. The insights help companies make better decisions about where to invest their money, what upgrades to launch, how to improve customer service, etc.
Now that you know what data scientists actually do, let’s see what data science subjects you have to study to become one.

Before we get into the syllabus of data science, let’s discuss some essential subjects you must study to become a skilled data scientist:
Databases and Big Data: In data science, you deal with massive amounts of data sets. So, you should know how to manage and process those large datasets. So here you learn databases (using SQL) and big data technologies like Hadoop and Spark.
Data Wrangling and Exploration: Real-world data is unorganized. Data wrangling helps you learn the process of cleaning and organizing data into a usable format. At the same time, data exploration involves studying the data and looking for initial patterns and relationships that might point toward deeper insights.
Data Analysis: Here, you learn how to carefully examine data to find meaningful information to support better decision-making. This is important because raw data is meaningless. Data analytics helps in extracting meaning from it and supports businesses, innovations, scientific research, etc.
Data Visualization: Numbers are boring and difficult to understand. That’s why here you learn how to use charts, graphs, and other visual tools to clearly communicate what you find in data analysis. It helps you tell stories and make complex information easier to understand.
Mathematics: This is the foundational subject in the entire data science syllabus. You will need a strong understanding of statistics, probability, linear algebra, calculus, etc. Statistics provides the tools to understand, analyze, and interpret data correctly. Linear algebra and calculus are important for developing and understanding the algorithms and models used in the field.
Programming: Data scientists use programming languages to implement everything they do. Python and R are the most popular languages you have to learn. This will help you write code to collect data, clean it, perform analyses, visualize data, build machine learning models, etc.
Machine Learning: This is an interesting thing to study. Here, you learn how to train computers to learn from data without being manually programmed. Machine learning includes various algorithms and methods that allow computers to find patterns, make predictions, and even take actions based on the data they are given.
Deep Learning: This is a subset of machine learning. Here, you learn about artificial neural networks that help in finding complex patterns from massive datasets. Deep learning has amazing applications, like computer vision, that enable image recognition for self-driving cars. It’s also found in AI chatbots and language models like ChatGPT.
Generative AI: Gen AI is the revolutionary AI model that can generate text, images, code, audio, and other types of data. It helps humans be more creative and automate repetitive processes. Here, you will learn about Generative Adversarial Networks (GANs), their applications, and how to build them using programming languages like Python.

The following data science course syllabus has been updated to meet current industry requirements. It takes you from the basics of data science to advanced concepts, teaching you all the in-demand tools you will need to solve real-world business problems.
This same syllabus is taught in Ivy Pro School’s Data Science and AI course with IIT Guwahati. This 45-week course also involves concrete projects to help you gain hands-on experience. So here we go…
The above data science course syllabus is strictly followed by Ivy Pro School’s Data Science and AI certification course. The course helps you learn industry-relevant skills, build a solid portfolio, and become job-ready in just 45 weeks.
This course is made in partnership with E&ICT Academy IIT Guwahati, where you are directly taught by professors on the IIT Guwahati campus. Besides, the IIT brand on your certificate gives you credibility and helps you stand out in interviews.
The online classes with live doubt-clearing sessions help you complete 50+ projects using industry-standard tools like SQL, Python, Keras, Tensorflow, OpenCV, Power BI, and Tableau. This is how you build an impressive portfolio that demonstrates your skills to employers.
Visit this page to learn more about Ivy’s IIT-certified Data Science and AI Certification course.
Team Apr 04, 2024 No Comments

Why be a data scientist? Well, the simplest answer is data science is a perfect career, with high job security, impressive salary, and work satisfaction.
Data science employment is projected to grow at an astounding 35% from 2022 to 2032, which is more than the average for all occupations. And approximately 17,700 annual openings are expected for data scientists over the decade.
A data science career involves collecting, cleaning, and analyzing complex datasets to uncover patterns, trends, and insights. Those insights are what help companies make better decisions about products, marketing, or business strategy.
But what makes data science such a hot career?
In this blog post, we will see in detail the 7 reasons to become a data scientist. By the end of this blog, you will know why you should choose this career and how you can start your journey.
If you are interested in maths, statistics, and computers, data science might be the path you should choose. It’s a career that challenges you, lets you learn new things, and helps you grow. Here are the top 7 reasons why data science as a career could be a great choice for you.
Yeah, if you are a skilled data scientist, you may get plenty of job offers. Why? Businesses are drowning in data. They have data coming from everywhere- from online purchases, social media, or market behaviors. But they don’t know what that data means.
So, companies need experts to study those data and uncover hidden patterns and trends for informed decision-making. Data scientists are the ones who make sense of that data. They study the raw numbers and transform them into insights that help organizations make better business decisions.
That’s how data science helps businesses gain a competitive advantage, putting the skill in high demand. Now you know why a career in data science could be a good option for you.
Let’s be honest. We all want jobs that pay not only our expenses but also help us fulfill our desires.
Data scientists definitely have that covered. According to Glassdoor, the average salary for data scientists in India is an impressive ₹12,59,993 per year.
The amount may vary depending on the job location and your experiences, but the earning potential in this field is seriously impressive. That’s a good reason to become a data scientist.
And it makes sense to pay skilled data scientists well. After all, they help the company make smart business decisions that directly impact a company’s bottom line.

Data science consists of many skills. You will study programming languages like Python and R, statistics, machine learning, data visualization, cloud computing, etc.
This versatile skill set opens many doors across various industries. You could become a data scientist in financial institutions, analyzing market trends. You can enter the healthcare industry and help innovate medical research. Or, if you love movies, you can take a role in movie studios to predict box office success and optimize marketing campaigns.
So, why be a data scientist? Well, because data science won’t trap you in a single career path. As your interests evolve, so can your job.
At its heart, data science is all about solving problems. You study the data to find answers to real-world questions.
And this process of problem-solving makes you good at the thing. You learn to break down complex challenges into smaller steps, think creatively, and find better solutions backed by data. That’s why a career in data science is a good option for those seeking to grow in life.
The ability to solve problems helps wherever you go. Whether you’re managing a project, stuck in a difficult situation at work, or simply figuring out which smartphone to buy, problem-solving skills are a lifesaver.
Why be a data scientist? Well, it doesn’t only add numbers to your bank balance, it also lets you make an impact on the world.
Data science lets you solve the world’s biggest problems that positively impact the masses.
As a skilled data scientist, you can help fight disease by analyzing medical records, improving education using insights about how students learn, or even combating climate change by analyzing energy consumption.
Working in data science means you can put your skills toward causes you really believe in. This is what makes the work meaningful, and it’s one of the best reasons to study data science.
One of the impressive reasons to become a data scientist is that this career not only teaches you technical skills but also improves your personality. For instance, data science projects teach you how to work in a team, communicate complex ideas, and manage different perspectives in a group.
This helps you develop your soft skills and become good with people. You also learn to manage professional and personal relationships. Besides, data science teaches you to be analytical, which helps you see situations from unique angles, think critically, and make smart decisions.

This is an underrated reason to become a data scientist. Job satisfaction is crucial for a happy and fulfilling life. And data science helps you achieve that.
You see, data science is a mentally stimulating career, full of puzzles to solve and new things to learn. You get to be creative, collaborate with people, and find solutions that make a real-world impact.
And then you see the tangible impact of your work, whether that’s a new product launch, detecting fraudulent financial transactions, or helping an NGO in fundraising. This fulfills you from within and makes you satisfied.
Now that you know 7 reasons to become a data scientist, I guess you must be excited about this career path and wondering where to begin. Well, here are three things you could do to start your career:
Taking online courses may be the best and fastest way to master this skill. You can consider Ivy Pro School’s executive certification course in Data Science and AI.
This program is in collaboration with IIT Guwahati, IBM, and NASSCOM, so you can already understand the importance of its certification.
Besides, professors from IIT and professionals from companies like Google, Amazon, and Microsoft will be teaching you so that you become job-ready.
In this online course with live doubt-clearing sessions, you will learn all the in-demand topics like Data Analytics, Visualization, Machine Learning, and tools like Adv. Excel, SQL, Python, Power BI, etc.
You already know the reasons to become a data scientist. Now, if you want to master this skill, visit this page to learn more about the Data Science and AI executive certification course.

Team Dec 26, 2022 No Comments
One of the most competitive and unpredictable business sectors is the insurance sector. It is highly related to risk. As a result, statistics have always been a factor. These days, data science has permanently altered this dependence. In this article, we will give you an insight into the various use cases of data science in insurance industry.
The information sources available to insurance firms for the necessary risk assessment have expanded. Big Data technologies are used to anticipate risks and claims, track and evaluate them, and design successful client acquisition and retention tactics. Without a doubt, data science and insurance easily compliment each other. In this article, we will have a look at the top 10 data science use cases in insurance.
Insurance companies are presently undergoing rapid digital transformation. With insurance digital transformation, a broader range of data is available to insurers. Data science in life insurance enables companies to assemble these data to effective use to drive more business and filter their product offerings. With that, let us have a look at the various applications of data science in insurance industry.
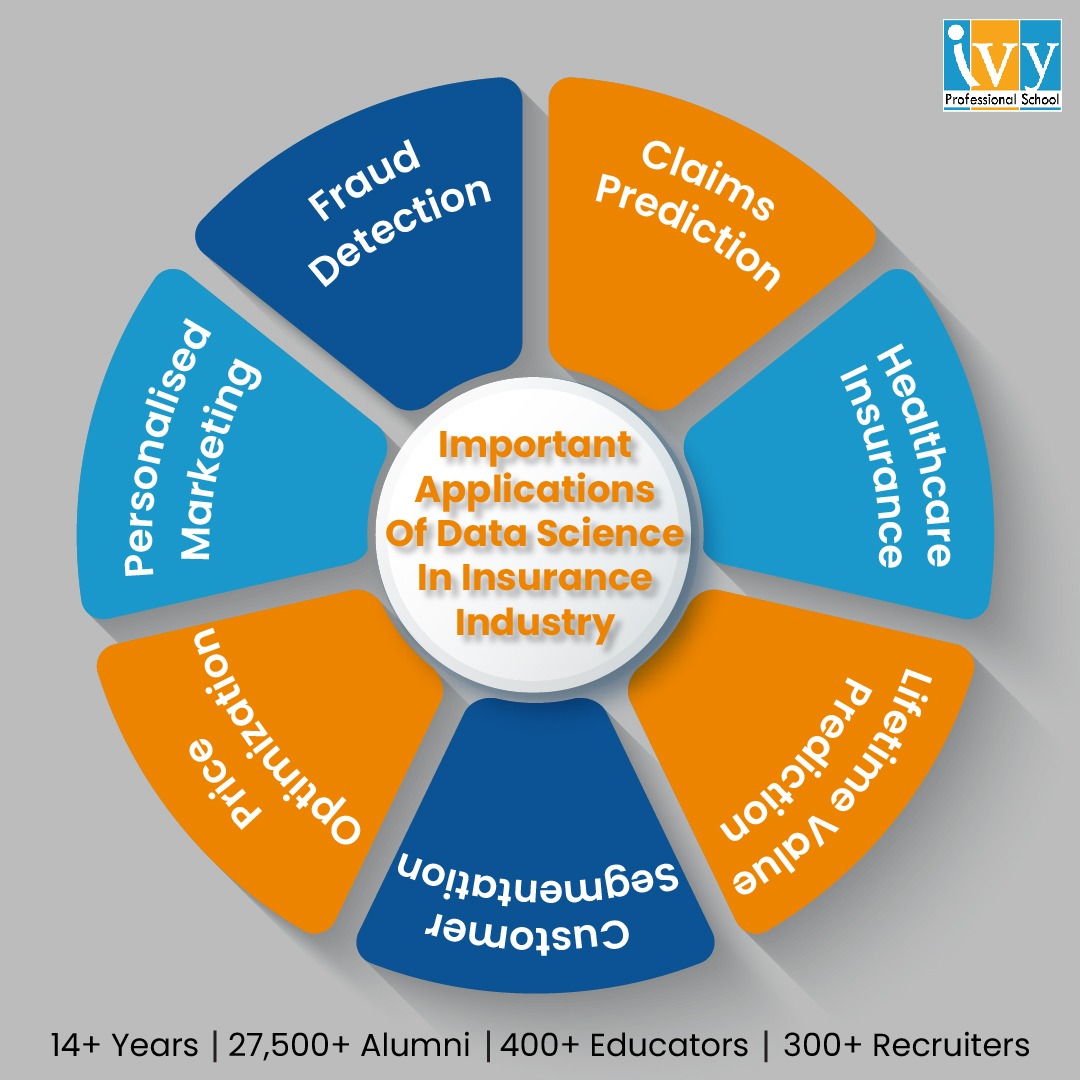
The first case among the various data science insurance use cases is the detection of fraudulent activities. Every year, insurance fraud costs insurance companies a great deal of money. It was able to identify fraudulent activities, suspicious relationships, and subtle behavioral patterns utilizing a variety of methods thanks to data science platforms and software.
A steady stream of data should be provided into the algorithm to enable this detection. Generally, insurance companies employ statistical frameworks for effective fraud detection. These frameworks depend on previous instances of fraudulent actions and use sampling methods to evaluate them. Along with that, predictive modeling techniques are used here for the purpose of analysis and also filtering of fraud scenarios. Evaluating connections between suspicious activities allows the company to identify fraud schemes that went unnoticed previously.
Customers are constantly eager to receive individualized services that completely suit their demands and way of life. In this regard, the insurance sector is hardly an exception. To satisfy these needs, insurers must ensure a digital connection with their clients.
With the aid of artificial intelligence and advanced analytics, which draw insights from a great quantity of demographic data, preferences, interactions, behavior, attitude, lifestyle information, interests, hobbies, etc., highly tailored and relevant insurance experiences are ensured. The majority of consumers like to find deals, policies, loyalty programs, recommendations, and solutions that are specifically tailored to them.
The platforms gather all relevant data in order to identify the primary client needs. Then, a prediction of what will or won’t work is made. Now it’s your turn to either create a proposal or select the one that will work best for the particular customer. This may be done with the aid of the selection and matching methods.
The personalization of policies, offers, pricing, messages, and recommendations along with a continuous loop of communication hugely contributes to the rates of the insurance company.
The idea of price optimization is complicated. As a result, it employs multiple combinations of different techniques and algorithms. Even though using this process for insurance is still up for debate, more and more insurance firms are starting to do so. This procedure entails merging data unrelated to predicted costs, risk characteristics, losses and expenses, as well as further analysis of that data. In other words, it considers the modifications compared to the prior year and policy. Price optimization and customer price sensitivity are so strongly related.
A qualitatively new level of product and service advertising has been reached thanks to modern technologies. Customers typically have different expectations for the insurance industry. Various strategies are used in insurance marketing to boost customer numbers and ensure targeted marketing campaigns. Customer segmentation emerges as a crucial technique in this regard.
According to factors like age, geography, financial sophistication, and others, the algorithms segment customers. In order to categorize all of the clients, coincidences in their attitudes, interests, behaviours or personal information are found. This categorization enables the development of solutions and attitudes especially relevant to the specific user.
CLV (Customer lifetime value) is a complicated factor portraying the value of the user to an entity in the form of the variation between the revenue gained and the expenses made projected into the whole future relationship with a user.
To estimate the CLV and forecast the client’s profitability for the insurer, consumer behaviour data is often used. The behaviour-based models are so frequently used to predict cross-selling and retention. Recency, the monetary value of a customer to a business, and frequency are seen to be crucial variables when estimating future earnings. To create the prediction, the algorithms compile and analyse all the data. This makes it possible to predict whether customers will maintain their policies or cancel them based on their behaviour and attitudes. The CLV forecast may also be helpful for developing marketing strategies because it puts customer insights at your disposal.
Healthcare insurance is a broad phenomenon across the globe. It generally implies the coverage of costs created by the accident, disease, disability, or death. In many nations, the policies of healthcare insurance are effectively supported by the governing bodies.
In this era of quick digital data flow, this niche cannot resist the influence of various data analytics applications. The global healthcare analytics market is constantly evolving. Insurance companies suffer from continuous pressure to offer better services and decrease their costs.
A broad range of data that includes insurance claims data, provider data and membership, medical records and benefits, case and customer data, internet data, and many more are assembled, framed, processed, and turned into valuable results for the healthcare insurance business. As a result, factors like cost savings, healthcare quality, fraud protection and detection, and consumer engagement may all greatly improve.
The future forecast piques the interest of insurance firms greatly. The potential to lessen the company’s financial loss is provided by accurate prediction.
For this, the insurers employ some complicated procedures. A decision tree, a random forest, a binary logistic regression, and a support vector machine are the main models. In order to reach all levels, the algorithms implement high dimensionality and incorporate the detection of missing observations as well as the discovery of relationships between claims. The portfolio for each customer is created in this way.
When talking about data science for insurance, we can conclude that modern technology is advancing quite quickly and entering many different industries. The insurance sector does not lag behind the others in this regard. Statistics have long been used in the insurance industry. Therefore, it is not unexpected that insurance companies are utilizing data science analytics in a big way.
The goal of using data science in insurance is much the same as it is in other industries: to improve the business, increase revenue, and lower expenses.
By now you must have understood the benefits data science has in the insurance sector. And not only in the insurance sector, but data science also finds relevance in almost all sectors of the world. So if you are aiming for a career as an insurance data scientist then this is the time. But before you enter this industry, it is important for you to grab a certificate in the same. Ivy Professional School offers great courses in data science and data engineering that you can enrol in. They offer expert-led courses along with complete placement assistance. Join Ivy and get to work on real-life insurance data science projects to make your resume more reachable to recruiters. For more details visit their website.
There are various applications of data science that include Claim Prediction, Healthcare Insurance, Lifetime Value Prediction, Customer Segmentation, Price Optimization, Personalised Marketing, and Fraud detection.
Using a plethora of data that is presently available, the insurance industry is seeing immense growth. Data anticipate how the industry will operate and also how its relation will be with its customers.
The job role of a data analyst in the insurance industry is to extract, convert, and summarise data as input for studies and reports, and data analysts design, alter, and run computer programmes. Examine the accuracy of the data that insurance firms offer, both in transactional detail and in aggregate, and assist the companies in fixing mistakes.
Team Dec 15, 2022 No Comments
The varied use of big data in all sectors of our life from transportation to commerce makes us realize how crucial it is in our daily lives. In the same way, data science is transforming the healthcare sector. In this article, we are going to have a look at how data science in healthcare can bring about a big and distinctive change.
Nearly 3.5 billion US dollars have been invested in digital health startups and in healthcare data science projects in 2017 enabling companies to meet their ambition of revolutionizing the general notion of healthcare that the world carries. If you are aiming to pursue a career in data science in the healthcare domain, then this is the ideal article for you as you will find many data science in healthcare jobs.
There are numerous factors that make data science crucial in healthcare in the present time, the most crucial of them being the competitive demand for important data in the healthcare niche. The collection of data from the patient via effective channels can help offer enhanced quality healthcare to users. From health insurance providers to doctors, all of them depend on the collection of factual data and its exact analysis to make effective decisions about the health situations of the patients.

Nowadays, diseases can be anticipated at the earliest stage with the help of data science in healthcare, that too remotely with innovative appliances boosted by ML (Machine Learning). Smart devices and mobile applications constantly assemble data about blood pressure, heartbeat rates, sugar, and so on transferring this data to the doctors as real-time updates, who can structurize treatments accordingly.
The significant contribution of data science in the pharmaceutical industry is to offer the groundwork for drug synthesis using AI. The metadata of the patient and mutation profiling is used for developing compounds that point towards the statistical correlation between the attributes.
Presently, AI platforms and chatboxes are structured by data scientists to allow people to get a better evaluation of their health by putting in several health data about themselves and getting a precise diagnosis. Along with that, these channels also assist users with health insurance policies and guide them to a better lifestyle.
The present-day scenario of the IoT (Internet of Things), which assures optimum connectivity is a blessing of data science. Presently, when this technology is applied to the medical arena, it can help supervise patient health. Presently, physical fitness supervises and smartwatches are used by people to manage and track their health. Along with that, these wearable sensor devices can be monitored by a doctor if they are given access and in chronicle cases, the doctor can remotely offer solutions to the patients.
Data scientists have developed wearable devices for public health that will allow doctors to collect most of the data such as sleep patterns, heart rates, stress levels, blood glucose, and even brain activity. With the help of various data science tools and also machine learning algorithms, doctors can track and detect common scenarios such as respiratory or cardiac diseases.
Data science technology can also anticipate the slightest alterations in the health indicators of the patients and anticipate possible disorders. Several wearables and also home devices as a part of an IoT network employ real-time analytics to anticipate if a patient will encounter any issue based on their current scenario.
A crucial part of medical services, diagnosis can be made more convenient and quicker by data science applications in the healthcare domain. Not only does the data analysis of the patient boosts early detection of health problems, but medical heatmaps pertaining to demographic patterns of issues can also be made.
A predictive analytics model uses historical data, evaluates patterns from the data, and offers precise predictions. The data could imply anything from the blood pressure and body temperature of the patient to the sugar level.
Predictive models in data analytics associate and correlates each data point to symptoms, diseases, and habits. This allows the identification of the stage of the disease, the extent of damage, and the appropriate treatment measure. Predictive analytics in the healthcare domain also helps:
Healthcare professionals seldom use several imaging technologies such as MRI, X-Ray, and CT Scan to visualize the internal system and organs of your body. Image recognition & deep learning technologies in health Data Science enable the detection of minute deformities in these scanned pictures, allowing doctors to plan an impactful treatment strategy.
Along with that, health data scientists are continuously working on the development of more advanced technologies to improve image analysis. For instance, the latest publication in Towards Data Science, the Azure Machine Learning channel can be used in training and optimizing a structure to detect the presence of three common brain tumors, Meningioma tumors, Glioma tumors, and Pituitary tumors.
As a data scientist in the healthcare and pharmaceutical industry, you will have to use your analytical skills to diagnose illness precisely and save lives. The huge amount of data that is sourced from the healthcare niche, from patient data to records kept by government authorities need a skilled analyst to handle it all.
The Covid-19 pandemic has lately shown how important data science in healthcare can be. Not only has data science enhanced the sampling and collection of data but also demonstrated global patterns in the spread of the infection, anticipating the next region where Covid would spread and how government policies can be structured to fight against the contagious disease effectively.
Regarding national-level healthcare, data scientists can help in monitoring the spread of the disease within the nation and coordinate in accordance with the authorities to send resources to the most affected areas.
In this section, we will outline the important responsibilities of a healthcare data scientist:
Evaluating the role of data science in healthcare is also an important responsibility for a data scientist in the healthcare domain. It includes modifying assembled data to align with the objectives and aims of the company.
Here are some of the top advantages of data science in healthcare that you can think of:

Perhaps the most crucial utilization of data science in healthcare is to decrease errors in the process of treatment via accurate anticipations and prescriptions. Since a substantial portion of data about the medical history of the patient is collected by the data scientists, that stored data can be employed for identifying symptoms of illness and offering a precise diagnosis. Mortality rates have significantly decreased since treatment options may now be tailored and care is given with better knowledge.
The development of medicine needs intensive research and time. However, both effort and time can be decreased by medical data science. Via the usage of case study reports, lab testing results, and previous medical and the impact of the drugs in clinical trials, machine learning algorithms can anticipate whether the drug is going to offer the desired impact on the human body.
In the case of quality treatment that needs to be taken care of, it is essential to create skill sets that can offer a precise diagnosis. Using predictive analytics, one can anticipate which patients are at greater risk and how to get in early to prevent serious damage. Along with that, the huge quantity of data requires to be managed skillfully to stop errors in administration, for which data science can be an ideal solution.
EHRs (Electronic Health Records) can be used by data science specialists in the medical arena to identify the health patterns of patients and stop unnecessary hospitalization or treatments, thus decreasing costs.
The 21st century is making lucrative use of data science in the healthcare niche to boost surgeries, operations, and patient recovery procedures. Apart from the developments in technology and the raised digitization of lifestyles, data science will also help in decreasing healthcare expenses, making quality medical amenities accessible to everyone.
We can conclude that there are various applications of data science in healthcare. The pharmaceutical and healthcare industry has heavily used data science for enhancing the lifestyles of patients and anticipating diseases at an early stage.
Along with that, with the advancements in medical image analysis, it is possible for doctors to find microscopic tumors that were previously difficult to find. Hence, it can be concluded that data science has revolutionized the healthcare sector and also the medical e
Now come to the section, where we can talk about how you can take your data science career to the next level. To establish your career in data science in the healthcare section you will have to have some sort of certification. The best institute for Data Science in this country is Ivy Professional School. Ivy offers a range of certifications that will help you in the future.